I’ve been doing some thinking about the mathematics and theory of classifications, as opposed to actually implementing particular classifications, and I’ve come to a few conclusions that I thought I’d share, in advance of a formal article.
The initial observation comes from the nearest neighbor technique that I’ve been making use of lately: given a dataset, and an input vector, the nearest neighbor algorithm uses the class of the vector that is most similar to the input vector as predictive of the class of the input vector. In short, if you want to predict what the class of a given input vector is, you use the class of the vector to which the input vector is most similar. This is generally measured using the Euclidean norm operator, but you could substitute other operators as well depending upon the context. This method works astonishingly well, and can be implemented very efficiently using vectorized languages like MATLAB and Octave.
The assumption that underlies this model is that the space in which the data exists is locally consistent. That is, there is some sufficiently small neighborhood around any given point, within which all points have the same classifier. The size of this neighborhood is arguably the central question answered by my initial paper on Artificial Intelligence, if we interpret the value of 
However, there are very simple examples where this assumption fails, such as the distinction between odd and even numbers. In fact, using the nearest neighbor approach will by definition produce an incorrect answer every time, since the nearest neighbor of an even number is an odd number, and the nearest neighbor of an odd number is an even number. Music is another example where the space is simply not locally consistent, and as a result, substituting a note with its nearest neighbor can produce disastrous results.
We can instead add additional criteria that would allow us to describe these spaces. For example, if we want to determine whether a given input integer is an even or an odd number, we can use an algorithm that searches for numbers within the dataset that have a distance from the input vector of exactly two. Similarly, we could require some minimum distance, and set a maximum distance. That is, vectors 


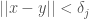
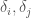
The question is whether we can infer the correct function given the dataset, which might not always be the case. That is, even if there is some computable function that allows us to say whether two points have the same classifier, we might not have enough data to determine whether or not this is the case. That is, the correct function might rely upon information that is exogenous to the dataset itself. Finally, this also suggests the question of whether it is decidable on a UTM (x) that we in fact have enough information to derive the correct function for the dataset in question, and if so, (y) whether or not there is a computable process that generates the correct function.
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
