Introduction
I’ve written about the symmetry of gravity in the past, but at the time, I had a much more convoluted theory of physics. I now no longer believe in Quantum Mechanics (at all), and no longer believe in time as anything other than a measurement of change, but you can still of course have time dilation even with this limited definition. See, A Computational Model of Physics, where I rewrote all of Relativity and most of known physics using objective time. Now that I’ve gotten this garbage out of my brain, I have a very simple theory of Dark Matter and Dark Energy.
Dark Matter is predicted to exist because cosmological observations deviate from Relativity. Now, real mathematicians and scientists have garbage cans, and when observation deviates from predictions produced by a model, we throw the model in the garbage. So the best explanation for Dark Matter, is that it doesn’t exist, and Relativity is wrong. We already know that Relativity is wrong for other reasons, e.g., the existence of the Neutrino, which has mass, yet a velocity of c, which is completely impossible in Relativity. But rather than accept this, ostensible scientists fuss about whether it’s exactly c, or some other handwaving nonsense, in defense of a physically implausible theory of the Universe, where everything depends upon anthropomorphic observers, as if electrons had a brain. So I think the best answer for Dark Matter, is that Relativity is wrong, and we need a new model of physics to explain cosmological observations.
In contrast, I don’t think Dark Energy depends upon Relativity. If however, it does depend upon Relativity, then we should start with the assumption that Dark Energy doesn’t exist, and build a new model of physics that is consistent with cosmological observations, otherwise known as doing science. All of that said, it dawned on me last night, that there might be something to Dark Energy, specifically, if we complete the symmetry of gravity.
Let’s start by completing the symmetry of gravity, which requires positive and negative mass, which we will denote as 

The obvious question is, where’s all this negative mass, and repulsive force? Well, first let’s consider that the Universe is quite old, and as a result, if we posit such a force has always existed, then this would eventually divide the Universe into at least two regions, one filled with mostly positive mass, and one filled with mostly negative mass. If this process is less than complete, then we should see some inexplicable acceleration due to interactions between positive and negative masses, which is consistent with Dark Energy.
Now, the SLAC 144 Experiment demonstrates that light on light collisions can produce matter-antimatter pairs. Further, we know that matter-antimatter collisions can create light. Let’s assume again that we’re in a positive matter region of the Universe, and as such, if we allow 


With that notation, now let’s posit the negative-mass versions of the electron and positron, which we will denote as 



If it’s an ordinary photon, then we arguably have a problem, because photon collisions have been shown to produce positive-mass electron positron pairs. That is, under this hypothetical, in the negative-mass regions of the Universe, when you do light on light collisions, you still get positive-mass pairs, which should eventually be kicked out of that region of space. In contrast, in the positive-mass regions of the Universe, when you do light on light collisions, you also get positive-mass pairs, but they stick around because it’s ordinary mass.
We could hypothesize that this is just the way things are, but we get an elegant potential solution to the source of Dark Energy if we instead posit the existence of negative-mass light 
 . Now we can consider the two possible values of
. Now we can consider the two possible values of  . If
. If  , then the statement asserts a truth value that is consistent with the assumed truth value, and there’s nothing wrong with that. If instead
, then the statement asserts a truth value that is consistent with the assumed truth value, and there’s nothing wrong with that. If instead  , then we have a contradiction, as noted above. Typically, when engaging in mathematics, contradictions are used to rule out possibilities. Applying that principle in this case yields the result that
, then we have a contradiction, as noted above. Typically, when engaging in mathematics, contradictions are used to rule out possibilities. Applying that principle in this case yields the result that  ,
, is the wavelength of the photon after scattering,
is the wavelength of the photon after scattering, 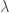 is the wavelength of the photon before scattering,
is the wavelength of the photon before scattering, 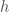 is
is  is the mass of an electron,
is the mass of an electron,  is the velocity of light, and
is the velocity of light, and  is the scattering angle of the photon. Note that
is the scattering angle of the photon. Note that  , which is the Compton Wavelength, is a constant in this case, but we will treat it as a variable below.
, which is the Compton Wavelength, is a constant in this case, but we will treat it as a variable below. , then
, then  evaluates to
evaluates to  , maximizing the function at
, maximizing the function at  . Note that
. Note that  is the difference between the wavelength of the photon, before and after collision, and so in the case of a
is the difference between the wavelength of the photon, before and after collision, and so in the case of a  bounce back, the photon loses the most energy possible (i.e., the wavelength becomes maximally longer after collision, decreasing energy,
bounce back, the photon loses the most energy possible (i.e., the wavelength becomes maximally longer after collision, decreasing energy,  , then
, then  , implying that
, implying that  . That is, the photon loses no energy at all in this case. This all makes intuitive sense, in that in the former case, the photon presumably interacts to the maximum possible extent with the electron, losing the maximum energy possible, causing it to recoil at a
. That is, the photon loses no energy at all in this case. This all makes intuitive sense, in that in the former case, the photon presumably interacts to the maximum possible extent with the electron, losing the maximum energy possible, causing it to recoil at a  angle).
angle). .
.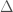 for any value of
for any value of 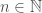 . If
. If  is prime, then we’re done. So assume that
is prime, then we’re done. So assume that  , for
, for  , and therefore,
, and therefore,  . The intermediate result will be to show that all numbers are either prime, or have at least one prime factor, which we will then use to prove the Fundamental Theorem of Arithmetic. As such, if
. The intermediate result will be to show that all numbers are either prime, or have at least one prime factor, which we will then use to prove the Fundamental Theorem of Arithmetic. As such, if 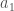 is prime, then we’re done. Therefore, assume
is prime, then we’re done. Therefore, assume  , for
, for  . We can of course continue to apply this process for increasing values of
. We can of course continue to apply this process for increasing values of  , generating decreasing values of
, generating decreasing values of 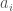 . However, there are only finitely many numbers less than
. However, there are only finitely many numbers less than  . Note that
. Note that  , and as such,
, and as such,  . Therefore, all natural numbers have at least one prime factor.
. Therefore, all natural numbers have at least one prime factor. , and the remaining factors,
, and the remaining factors,  , i.e.,
, i.e.,  . Note that
. Note that 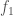 cannot be prime, so we can therefore run the algorithm above on
cannot be prime, so we can therefore run the algorithm above on  , and another remaining factor
, and another remaining factor 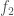 , such that
, such that  . Note that it must be the case that
. Note that it must be the case that  , and in general,
, and in general,  , and therefore it requires fewer steps to calculate each successive prime factor. Because the number of steps is always a natural number, this process must terminate. Therefore,
, and therefore it requires fewer steps to calculate each successive prime factor. Because the number of steps is always a natural number, this process must terminate. Therefore, 
{kind=link}
{kind=link}