Years ago when I was living in Sweden, I discovered what seems to be an original number I called 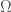 , which is defined as the logarithm of
, which is defined as the logarithm of  , i.e.,
, i.e.,  . You can read more about it in this paper [1], where I present a few theorems etc., and introduce a machine that actually has storage equal to bits. The machine would require infinite time to construct, but so does a true UTM, which has an infinite tape. Similarly, the machine described in [1] has countably many states, and therefore, is the amount of information that can be stored on any machine that has countably many states. As a consequence, has intuitive physical meaning, and therefore, we have a reason to assume it exists.
. You can read more about it in this paper [1], where I present a few theorems etc., and introduce a machine that actually has storage equal to bits. The machine would require infinite time to construct, but so does a true UTM, which has an infinite tape. Similarly, the machine described in [1] has countably many states, and therefore, is the amount of information that can be stored on any machine that has countably many states. As a consequence, has intuitive physical meaning, and therefore, we have a reason to assume it exists.
I was thinking about the number again while food shopping, and I realized it fits the continuum hypothesis perfectly. I show in [1] that there is no set with a cardinality of , and that as a logical consequence, must be something other than a number. The natural answer is that is a quantity of information. We can think about zero the same way, as 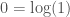 , which satisfies our intuition, that zero represents no substance. Further, in this case, zero is the amount of information contained in a system that has exactly one state. This is plainly true, since a system that never changes cannot meaningfully store information, and instead simply exists. Similarly, is not the cardinality of any set, and therefore not a number, but it is nonetheless a meaningful quantity of information. As a consequence, it’s arguable we cannot perform a number of operations a number of times equal to (see below for more on this topic).
, which satisfies our intuition, that zero represents no substance. Further, in this case, zero is the amount of information contained in a system that has exactly one state. This is plainly true, since a system that never changes cannot meaningfully store information, and instead simply exists. Similarly, is not the cardinality of any set, and therefore not a number, but it is nonetheless a meaningful quantity of information. As a consequence, it’s arguable we cannot perform a number of operations a number of times equal to (see below for more on this topic).
All of that said,  is defined, because that is simply the product
is defined, because that is simply the product  , taken a countable number of times. Basic assumptions of arithmetic imply the following inequality:
, taken a countable number of times. Basic assumptions of arithmetic imply the following inequality:
 .
.
Because  , it must be the case that
, it must be the case that  .
.
However, taking the logarithm, we have the following:
 .
.
Corollary 1.9 of [1] proves that is unique, in that there is no other number of bits  such that
such that  , for all
, for all 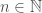 and
and  . Therefore,
. Therefore,  does not exist. As a result, we learn nothing from taking the logarithm, since is the smallest infinite quantity. However, we can conceive of a countable collection of machines with bits of storage, and you can therefore easily show that
does not exist. As a result, we learn nothing from taking the logarithm, since is the smallest infinite quantity. However, we can conceive of a countable collection of machines with bits of storage, and you can therefore easily show that  .
.
Most interestingly, it must be the case that,
 .
.
Therefore, because of the uniqueness of , if the continuum hypothesis is true, the above inequality is the unique solution. Note that the continuum hypothesis has been proven independent from the standard axioms. Further, note that this would arguably require assuming we can perform an operation times, which is not an intuitive assumption. You could argue that we already permit the products and powers of real numbers, which are plainly not cardinals, but we can ascribe physical meaning to such processes through approximation using finite decimal rational numbers, which are the ratios of cardinal numbers. In contrast, has no approximation.
A few other thoughts,  , for all , and you can appreciate this by simply reading [1], even though it’s not proven in [1]. However, I realized tonight, it’s arguable that
, for all , and you can appreciate this by simply reading [1], even though it’s not proven in [1]. However, I realized tonight, it’s arguable that  is not defined. In contrast,
is not defined. In contrast,  is just the number of bits contained in two machines, and more generally,
is just the number of bits contained in two machines, and more generally,  is simply the number of bits contained in
is simply the number of bits contained in  machines. It’s not clear how to think about a collection of machines in number, precisely because there is no set that contains elements. Therefore, integer powers of are arguably undefined. However, as noted above, we can conceive of a countable collection of machines, and you can easily show that . I’m nearly certain I unpacked all this stuff in Sweden, in my notes, but I didn’t include it in [1], because I was working on completing Black Tree AutoML. That said, though I doubt anyone has done any work on this in the interim anyway, I discovered this stuff around 2018.
machines. It’s not clear how to think about a collection of machines in number, precisely because there is no set that contains elements. Therefore, integer powers of are arguably undefined. However, as noted above, we can conceive of a countable collection of machines, and you can easily show that . I’m nearly certain I unpacked all this stuff in Sweden, in my notes, but I didn’t include it in [1], because I was working on completing Black Tree AutoML. That said, though I doubt anyone has done any work on this in the interim anyway, I discovered this stuff around 2018.

{kind=link}