Dear Readers,
I’ve decided to fund my A.I. venture using Kickstarter, as it is the most attractive avenue to keep things moving, since it effectively allows me to sell discounted versions of my software upfront, and keep whatever proceeds I raise:
https://www.kickstarter.com/projects/blacktreeautoml/black-tree-automatic-machine-learning
There are four levels of funding:
1. $5
2. $25
3. $100
4. $500
Each gives one person a life-time commercial license to use increasingly sophisticated versions of my software, that I plan to charge monthly for once the software is released on Apple’s App Store.
The idea is to completely democratize access to A.I., by taking the software to market using the Apple App Store, offering it at a small fraction of what competing products charge, the idea being that a global audience that pays a small sum per month is more profitable than marketing only to enterprise clients that pay large sums of money –
The plan is to sell the McDonalds of A.I., for $5 or $50 per month, depending on what you need.
There’s a video on the Kickstarter page that demonstrates the software, but at a high-level, it is, as far as I know, the most efficient machine learning software on Earth, and incomparably more efficient than Neural Networks, accomplishing in seconds what takes a Neural Network hours. It is also fully autonomous, so you don’t need a data scientist to use it –
Anyone can use it, as it’s point and click.
This will allow small and large businesses alike to make use of cutting-edge A.I. that could help manage inventory, predict sales, predict customer behavior, etc.
I’ve also shown that it’s capable of diagnosing diseases using medical imaging, such as brain MRI’s, again with the same or better accuracy as a neural network:
https://derivativedribble.wordpress.com/2021/09/23/confidence-based-prediction/
Because it can run quickly on a laptop, this will allow for medical care to be delivered in parts of the world where it is otherwise unavailable, and at some point, I plan to offer a free version for exactly this purpose.
Your support is appreciated, and it’s really going to make a difference.
Best,
Charles


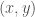
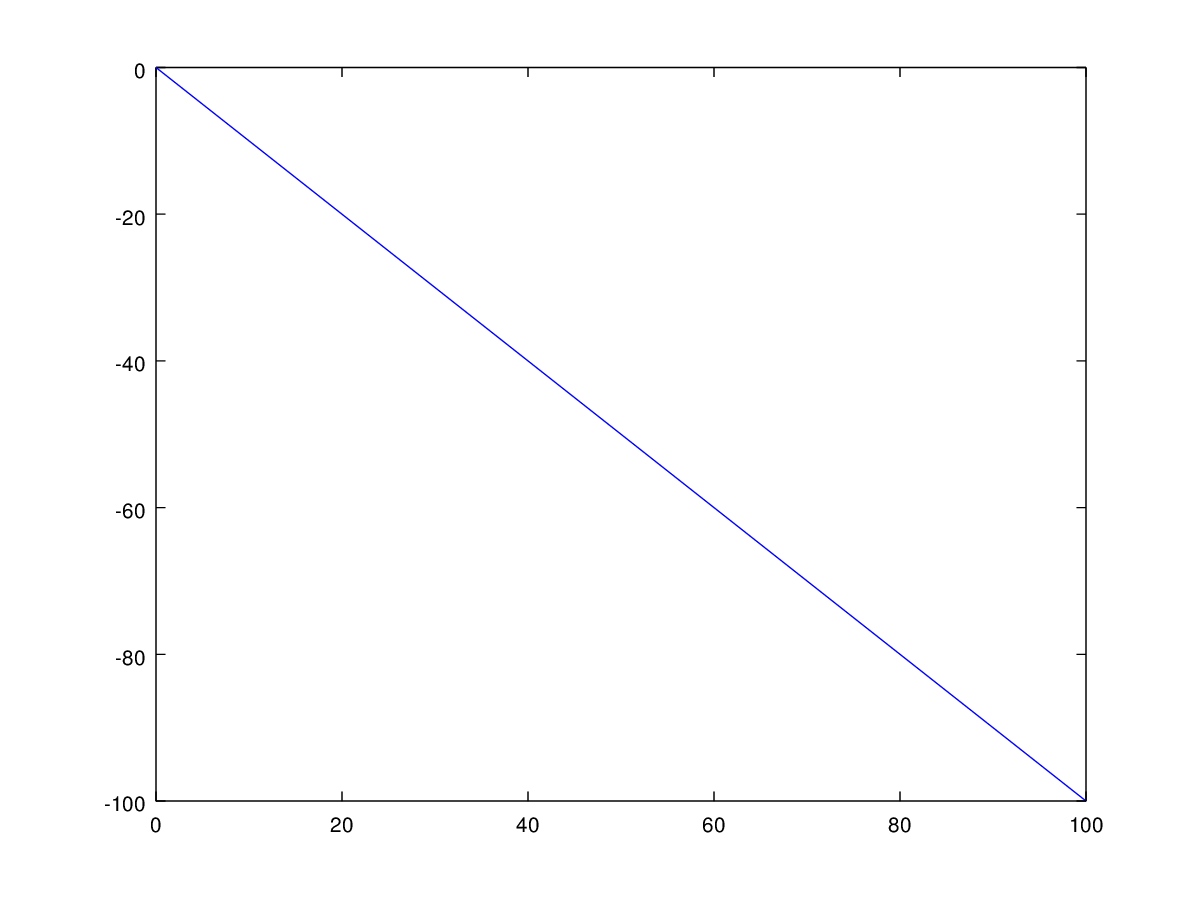



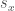
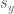
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002)
