Globalization has dramatically improved standards of living for entire populations in both developed and developing economies alike. Complex goods like laptops and smartphones can now be produced at incredibly cheap prices, allowing ordinary people to keep in touch, enjoy both traditional and new forms of media, and make payments quickly, safely, and easily. These communication networks and devices are not only beneficial to human welfare, but are also a tremendous achievement for humanity as a general matter, and mark the first steps towards a single, truly integrated global economy.
But globalization has also altered the fundamental balance of power between labor and capital. One of the most alarming consequences of this new balance of power is the growing divide between the incomes of the professional class and the working class, and the even larger divide between the incomes of the investor class and everyone else. Though economies are complex systems, the fundamental cause of these income gaps can be traced to the relatively lower price of labor in many of the markets where these goods and services are now sourced, as compared to the price of labor in developed economies. Unfortunately, this relatively lower price of labor is in many cases due to the local absence of social and political institutions necessary to protect people from being exploited, meaning that human beings can in some markets be forced to work for little or no compensation, often in unsanitary, and unsafe conditions. At the same time, global supply chains have grown to be so complex, that even well-intentioned corporations have to dedicate significant resources to ensure that their products are produced without the use of exploitative labor, or at a minimum, to ensure that their supply chain is in compliance with modern anti-slavery laws.
Though there was some outrage over the Libyan slave auctions that made it to the headlines in 2017, consumers seem generally oblivious to the fact that in 2018, millions of people are being forced to work for little or no compensation. The International Labor Organization estimates that on any given day during 2016, there were 40.3 million people globally that were used as slaves.
Slavery is now, without question, an integral part of the modern global economy.
The Single Market
Globalization is gradually creating a single, global market for goods and services. As the market for labor became globalized, the effective supply of labor increased, causing the price of low-skill labor to generally decline in developed economies (see page 25), eventually causing the income generated by capital to come very close to parity with the income generated by labor in developed economies. This means that, as a class, the developed world’s investors and property owners now generate almost as much income from their capital as working people generate through their labor. Similarly, financial markets have become increasingly correlated globally, as capital is now generally free to move across borders, and global investors concentrate their capital with a relatively small number of large, global asset managers.
The power gap between the global investor class and the working class in developing economies is even more pronounced. Historically, many developing economies have contributed only marginally to the overall global economy. As a result, many governments in developing economies lack the political and social institutions necessary to protect their populations from being exploited by foreign capital, particularly in rural areas, where children have little to no access to formal education (see pages 20 to 21).
As markets became more integrated over the last thirty years, small, developing economies began to contribute meaningfully to the global economy, in turn attracting significant investments from large corporations and wealthy individuals alike. This has of course created wonderful opportunities for many people in developing economies, and lifted entire populations out of poverty in China, India, Brazil, and elsewhere. But at the same time, the lack of political and social institutions in many developing economies has created an environment where human trafficking, exploitative labor, and even outright slavery are occurring on a mass scale.
While these may sound like marginal, outlier cases, it is important to remember how large the world’s population is right now: approximately 7.6 billion people. This means that bad outcomes with low probabilities still involve millions of people being harmed. Left unchecked, this dynamic will inevitably lead to a shift in normative expectations and behaviors, where consumers and businesses alike grow accustomed to the idea that some amount of abusive or exploitative labor is inherent in the production of a modern product, simply because production is now so complex, that it is impossible to sift through the entire supply chain and uncover all the bad actors. In economic terms, just as the price of labor appears to be converging to a global average, the culture of labor could also converge to a global average, as the consumer class collectively grows indifferent to how the products and services they use are being produced.
By analogy to the financial markets, when credit markets heat up, the price of borrowing comes down, meaning that borrowers pay lower interest rates on their loans as lenders compete with each other. But something else tends to happen under these conditions: the terms of the loan documents become more favorable to the borrower, as lenders find other, softer ways to compete with each other, beyond pricing. Similarly, states that all have a comparable cost of labor will find other, “softer” ways of competing with each other, beyond the price of labor. In developed economies, states might compete with tax incentives, or regulatory exemptions. For example, individual states within the U.S. are now in the process of competing for Amazon’s new headquarters, since Amazon’s new home state will almost certainly benefit from a large investment by the company, leading to new jobs, infrastructure development, and tax revenues. This creates an incentive on the part of elected representatives to offer terms beyond the price of local labor that Amazon will find attractive. In developing economies, or in resource rich, but otherwise impoverished economies, the process of courting capital by state officials lacks the oversight and legal roadblocks that developed economies have put in place over hundreds of years of commerce and investment. This results in an environment where bribery and corruption are viewed as standard practices in many markets.
Globalization has of course also given rise to global corporations, meaning that local corruption is no longer a local problem, as large, global brands do business with small, often corrupt local regimes, whether directly, or indirectly through their supply chains, or other business relationships. This again runs the risk of a type of normative averaging, where global businesses become desensitized to corruption, bribery, and abuse, whether through their own direct contact with corrupt businesses, regimes, and individuals, or through the awareness of more attenuated relationships.
One of the benefits of a free market economy is that there is no single, conscious architect of its outcomes, which means that complex economic decisions are determined by the wisdom of crowds, through the idiosyncratic preferences and decisions of a growing population of billions of individuals acting without any collective plan. In contrast, the management of capital has become more and more concentrated into a relatively small number of similarly minded firms and individuals, giving these firms and individuals significant control over the world’s publicly traded companies, and private companies (see page 15). As the income generated by capital inches closer to parity with the income generated by labor, the net effect is that billions of uncoordinated individuals will be seeking employment either directly at an asset management company, or indirectly through a company controlled by an asset management company, ultimately financed by a global investor class that has a collective income that is comparable to the total income generated by these masses, but much greater, and more coordinated, economic power.
The Decline of the Regulatory State
Bernie Madoff is a truly shameless man, whose life story is, nonetheless, in some sense, the archetypal American success story. He grew up in Queens, New York, in a working class family, went to a public high school, graduated from college, all the while without achieving any notable academic distinctions, and started what was, in fairness to him, a successful and innovative financial services firm. He eventually scrambled all the way up from the hinterlands of the pink sheets, to the Chairman’s office of the Nasdaq exchange, becoming a very rich man along the way. But Madoff’s appointment as Chairman meant more than just additional compensation and prestige for Madoff as a businessman. The appointment made Madoff a fiduciary of society as a whole. Nasdaq’s exchanges are not ordinary businesses, but are instead vital pieces of financial infrastructure, akin to public utilities: nearly $100 billion (USD) worth of transactions occur every day on Nasdaq exchanges. Madoff’s appointment as Nasdaq’s Chairman meant that he had been entrusted with one of the most important pieces of machinery in the global economy: a tool that, if misused, could easily harm millions, and possibly billions, of human beings. More worrisome, Nasdaq is a self-regulatory organization, meaning that, in practical terms, Nasdaq itself as an institution can write and enforce many of the regulations that govern the conduct of the individuals that make use of its exchanges. Putting all of this in context, Madoff’s appointment as Chairman of Nasdaq borders on the comical, given that he is, of course, now known to be one of history’s greatest financial criminals.
The stark contrast between the responsibilities of Bernie Madoff’s role as Chairman, and the gross deficiency of his character, is itself evidence of regulatory dysfunction. In a well-functioning regulatory environment, an outcome where such a reprehensible man is given such enormous responsibility should have a near-zero probability of occurring. We could of course argue that, with time, even low probability events must eventually occur, and so, perhaps Madoff’s chairmanship was an outlier event that is not really evidence of anything other than a slippery man that weaseled his way to the heights of his industry. Unfortunately, this cannot be the case, as the Securities and Exchange Commission, who is ultimately responsible for Nasdaq, was warned that Madoff was likely engaging in financial crimes. This warning, together with the scale, and brazen nature of Madoff’s crimes, make it impossible to conclude that the regulatory environment in which Madoff operated was functioning properly.
The financial crisis of 2007-2008 is further evidence of a broken and dysfunctional regulatory state. While there was no shortage of discussion on the “complex” products that banks were using to “place bets” on the U.S. housing market, the reality is that mortgage-backed securities (the assets at the heart of the financial crisis) have been in use since the 1970’s in the U.S. They are of course unfamiliar to most people, but this is no different than the generally arcane products that allow any industry to function. Most people have no idea how an airplane engine works, yet people fly every day. Similarly, most people have absolutely no idea what happens at a typical bank, yet they make use of banking services every day.
When a plane crashes, the public wants to be reassured that there is nothing wrong with planes generally, but that there was something wrong with the particular plane that crashed, or the particular pilot that caused the plane to crash. If such a narrative didn’t exist, the economy would likely be crippled, as people would no longer trust aviation as a safe means to transport human beings and goods. Similarly, the financial crisis created demand for a narrative that would allow society and regulators alike to blame particular firms, individuals, circumstances, and products, so that society could get back to using banks without having any idea as to how they actually function. Such a narrative is to some degree necessary, because banks need to be able to function, whether or not people understand how they work, and ordinary, everyday people need to be able to trust the financial system with their paychecks and savings – the very means by which they feed, clothe, and house themselves and their families.
Whether we can trust our banking system, and our financial system generally, is in part dependent upon our confidence in banking and securities market regulators. Unlike individuals that have jobs at private firms, regulators are paid to act in the interests of society as a whole, and to put their own personal, economic interests aside. Of course, regulators are human beings, with all the psychological, moral, and intellectual shortcomings that are characteristic of our species. And so it would be not only foolish, but also unfair to expect regulators to conduct themselves in some sort of saintly manner that is in its nature different from that of an ordinary person. But having low expectations doesn’t imply that we shouldn’t design regulatory environments with the worst of humanity in mind. In fact, it implies that we should have laws in place that prevent regulators from acting on their worst instincts, or in a manner that creates public harm, in exchange for private benefit.
The scale of the financial crisis, and the fact that, again, regulators had reason to suspect something was wrong, together with the fact that many market participants saw the crisis coming and profited from it, suggest quite plainly that the U.S. regulatory system is broken. The narrative that was weaved after the financial crisis was that prior banking and securities laws were inadequate, and that the financial reforms that have taken place since then have addressed these inadequacies. From this we are to conclude that a new financial crisis is unlikely, since regulators are now equipped with the tools necessary to stop such an event from occurring again. This narrative, however, assumes that the inadequate regulations were in fact the sole cause of the financial crisis, when in fact the crisis was at least in part due to a much more mundane cause – banks were financing long term, illiquid assets with short term capital. When that short term capital dried up, banks had to scramble to raise capital, and some of them didn’t survive that process. This narrative also assumes that regulators will actually make use of these new tools in order to stop another financial crisis from occurring, which is obviously a very cynical line of reasoning, but the reality is that regulators, like all other rational human beings, are, generally speaking, primarily concerned with their own careers and their own lives. As a result, it is not necessary for regulators to be corrupt, in the classic, criminal sense of the word, to produce bad outcomes, but rather, to simply, whenever it is legally possible, maximize their own private benefit, possibly at the expense of the public good.
It is an open secret that there is a revolving door between financial regulators and financial institutions. And again, this does not imply that the individuals that make the skip from regulator to financier are engaging in anything that rises to the level of criminal behavior. More likely, they are simply looking out for each other in a manner that maximizes private gain, possibly at the expense of the public good. In fact, such an environment doesn’t even require deliberate, coordinated action in order for a tragedy to occur. If a sufficient number of regulators are acting in their own self interest, or ignoring, or simply not caring about their jobs, it creates a regulatory environment where regulatory diligence is low, and the probability of a financial crime, or financial crisis, is therefore high.
For those regulators that do take their jobs seriously, of which there are undoubtedly many, the prospect of regulating a global corporation must be unnerving. In 2015, Apple’s annual revenue was approximately $234 billion (USD). Though not entirely analogous, for context, the gross domestic product of Finland for 2015 was approximately $232 billion. This means that, in practical terms, the revenue raising power of Apple Inc. is on par with that of a highly developed, sovereign European state. Finland is of course a small country compared to the United States, but it is nonetheless a first-rate nation with a high-functioning government, education system, infrastructure, and military. All of these institutions within Finland are beholden to the people of Finland, and operate for the benefit of the people of Finland. In contrast, Apple Inc. is a corporation that operates for the benefit of its global shareholders, who have no obvious, collective interest other than making a profit. Apple Inc. is in this sense an extremely wealthy state without a land, a people, a parliament, or a purpose, beholden only to what is shaping up to be a single class of global investors.
Apple is of course not alone, and is instead but one example of a modern, global corporation that has all the money and power of a sovereign state, but none of the obligations or cultural history of a sovereign state. The world’s largest financial institutions are of course comparable in scale, complexity, and power, but they are, in contrast to Apple, much older institutions, with deep, historical ties to governments all over the world. This makes the task of regulating a financial institution a precarious one for the individual human beings employed by financial regulators. Imagine working as a government regulator, and having the nerve to tell another person that works for a giant financial institution (who in a few years could very well be your boss, or alternatively, offer you a high-paying job) with tens, or even hundreds of thousands of employees, and the financial resources of an E.U. member state, that they need to change their behavior: this is not going to be the average case. So as a practical matter, the power imbalance between individual regulators and the institutions they regulate instead ensures that individual regulators will be cautious in their interactions with management-level contacts at the institutions they regulate, and only go for blood when instructed to do so by their superiors.
Common sense suggests that such an environment will inevitably lead to bad outcomes, and recent history is, not surprisingly, in agreement with common sense. But instead of questioning the obvious problems created by the incentive and power structure of the current regulatory environment, and the power imbalance between individual regulators and the massive, global corporations they oversee, lawmakers and enforcement agencies tend to focus on headline grabbing cases, emphasizing outrage, and short-term justice, rather than making sensible, substantive reforms. Frankly, this is all done to create the appearance of a well-functioning regulatory state, and to distract from its glaring, and destabilizing shortcomings. Lesser known corners of the U.S. financial system, such as underfunded state and local pension plans, get almost no popular attention at all, and arguably lack a competent regulator in the first instance. Yet, they could pose serious risks for the financial markets as demographics shift, causing pension liabilities to become due to beneficiaries.
This is not to say that the post-crisis financial reforms were superficial in nature. To the contrary, the reforms brought about by the Obama administration were vast in scale, very expensive to implement, and fundamentally changed many business lines at financial institutions, and the financial market’s structure generally. But the fundamental relationship between financial regulators and financial services firms remains generally unchanged, and as a result, incumbent firms will likely continue to operate with effective impunity, while occasionally, individual actors will of course, probably be punished, and made an example of, in order to create the superficial appearance of justice, when in reality, a regulatory system that functions properly should never produce these types of outcomes in the first instance.
Though there is unfortunately no shortage of examples, Bernie Madoff is the archetypal case of the dysfunction of the U.S. regulatory and justice system: rather than stop his criminal conduct from occurring in the first instance, or prevent it from reaching a dangerous scale, he was instead arrested and convicted after the fact, and sentenced to 150 years in prison. These types of sentences, that pointlessly run longer than any human lifetime, especially for an already old man, say a lot about how justice now works in America. It’s not a justice system that actually prevents bad outcomes, but is instead a justice system that gives us something to marvel at, and talk about, after the harm has already been done – the scale of Madoff’s crime, his outrageous lifestyle, all culminating in a bizarre, and meaninglessly long jail sentence. The U.S. justice system is, as a general matter, now rooted in spectacle, not substance, and the results reflect this.
The Rise of Criminal Business Conduct
The Grey Market
People that are not themselves criminals generally have a very romanticized notion of what it is to be a criminal. This is only natural, since if you are not a criminal, you probably don’t interact with criminals on a regular basis, and so you’ll fill in the mental gaps as to how criminals behave with bits gleaned from movies, novels, and documentaries, all produced by people that are probably not criminals themselves. As a result, people that grow up with light bulbs, bank accounts, and clean underwear, are in this sense detached from what ordinary life is like for people that have to use violence to survive on a daily basis. All of this produces a mental portrait of criminality collectively painted by a group of people that are generally out of touch with how remarkably disgusting, and incredibly brazen, criminally minded human beings can be.
Prior to the integration of the global economy, this criminal knowledge gap didn’t really matter much, since criminal conduct was largely a local issue, dealt with by local authorities who were experts in the behavior of local criminals. But just as globalization broke the shackles of geography for businesses, spawning the birth of giant, global corporations, globalization has also knocked down the gates for criminal enterprises as well, allowing intrepid, criminally minded individuals and organizations to conduct business on an unprecedented, global scale. And because otherwise legitimate global firms now interact with small, often corrupt local regimes, there are likely more interactions taking place between large global institutions, and quasi-criminal organizations and corrupt state actors, blurring the lines between commercial and criminal conduct. As a general matter, this means that local corruption is, again, a global problem.
There are some astonishing recent examples of this “grey market” for goods and services, where otherwise legitimate firms and individuals engage the services of others that perform deliberately criminal, or potentially criminal acts on their behalf. For example, Harvey Weinstein apparently hired former Mossad agents to bully women he had abused in an effort to cover up his criminal sexual conduct. Save for his sex life, Harvey Weinstein does not appear to have been otherwise engaged in a criminal enterprise, but he was nonetheless able to find, and pay, others to perform potentially criminal acts act on his behalf.
Bloomberg recently published an in-depth piece about the mystery of an oil tanker that was hijacked under suspicious circumstances while carrying $100 million (USD) worth of oil. The investigation that followed, carried out by the company that provided the insurance for the ship, spurred what appears to have been a dramatic assassination of the insurance inspector: one day after the insurance inspector reported back that the hijacking did not appear to have been carried out by ordinary pirates, a bomb went off in his car, killing him instantly.
For the all the purported rough and tumble of Wall Street during the 1980s, the “barbarians at the gate” probably didn’t deal with car bombs, or Mossad agents, so it seems that being an insurance inspector or an actress in 2018 requires more grit than being a private equity titan did in the 1980’s.
There are also cases of criminals infiltrating legitimate businesses in order to use them for criminal ends. In an age where people’s personal information (text messages, photos, internet history, etc.) can all be used to blackmail them, otherwise ordinary people with access to sensitive information, or a particular set of skills, could find themselves under the thumb of organized crime. Bloomberg ran yet another in-depth piece about how two Belgian IT consultants, both earning six-figure salaries in their professional careers, ended up being coerced into working with Turkish mobsters, using their IT skills to steal access codes to shipping ports, ultimately to facilitate the smuggling of cocaine and heroin on a mass scale.
Similarly, financial institutions can be used by economically or politically motivated individuals willing to commit financial crimes, whether for a profit, or to advance a political agenda. The complexity and scale of financial institutions, and the global financial markets generally, allow connections between otherwise legitimate firms and criminal organizations, or rogue states, to go undetected through obfuscation. Financial institutions that facilitate money laundering, or transactions that run afoul of sanctions, in this manner can do mass harm, funneling enormous sums of money to dangerous individuals, and undermining the effect that sanctions are intended to have on the states and individuals they are intended to punish.
Donald Trump’s Business Network and Political Campaign
For all his anti-globalist rhetoric, Donald Trump is in reality a globalist businessman. His real estate, entertainment, and other businesses are all part of a sprawling global network of companies that have benefited from the same low barriers to trade that he is now putting in the cross-hairs. Though Trump has made good on his campaign promises, and has begun to impose trade tariffs, he is conspicuously silent on the tremendous sums of money that cross international borders every day through the global financial system.
According to several reports by the Financial Times, it now seems that Trump has personally benefited significantly from the types of grey market transactions that have been facilitated by the emergence of a global, decentralized financial system that lacks a single, competent, global regulator. As if taken from the pages of a poorly written screenplay, the sordid list of characters involved in Trump’s extended business network includes the KGB itself, shady Canadian real estate developers, thugs (including Felix Sater, who served time in prison for stabbing an associate in the face), and of course, porn stars. Despite the scale, and to his credit, the generally public, and often ostentatious, nature of Trump’s businesses, no competent regulator thought it necessary to stop Trump’s financial dealings before they occurred.
Similarly, no competent regulator was able to identify and stop the proliferation of political disinformation on Facebook that occurred during the 2016 elections, which increasingly appears to have been done at the direction of the Russian state. That Facebook could be used as a tool to alter election outcomes seems obvious in retrospect, since it is a source of news and information for billions of people. That Facebook could be exploited by foreign or domestic groups looking to deliberately alter election outcomes also seems obvious in retrospect. Yet, there is no single, competent regulator for a company like Facebook, despite its power to influence the thoughts and opinions of billions of people globally. You could of course argue that Facebook’s power to shape the thoughts and opinions of its users is speculative, but this is nonsense: businesses and political campaigns alike pay Facebook billions of dollars in ad revenues precisely because Facebook can, by exploiting the vast body of sensitive, personal information it has on its users, change the way people think about products, services, other people, and issues.
The Dark Web
The same communication and payment infrastructure that facilitated the rise of global trade also gave rise to a decentralized, generally anonymous communication and payment network loosely referred to as the “Dark Web”. Intelligence agencies, criminals, and increasingly, children without direct access to the black market, all use services like Tor to communicate and transact with each other over the Dark Web, on a global, generally anonymous basis. The Dark Web has commoditized the black market, removing many, and in some cases nearly all, of the logistical barriers to purchasing drugs, guns, sensitive information, and even human slaves.
Though law enforcement agencies are certainly aware of the Dark Web, it is a global, and decentralized network of servers and individuals, and as a result, there is no obvious law enforcement, legislative, or regulatory solution to the criminal conduct taking place on the Dark Web. Global law enforcement officers have, however, made significant busts, including the break up of Silk Road, and a recent bust involving the FBI and Europol, in which two Dark Web sites dealing primarily in drugs, weapons, and malware were taken down. One of the sites, AlphaBay, reportedly could have had annual revenues of several hundred million dollars. Despite these potentially large revenues, the AlphaBay case resulted in only a few arrests, since the individuals who were apparently running the site were few in number, and scattered all over the world.
Like a leanly staffed tech startup, or hedge fund, global communications and payment networks like the Dark Web allow a handful of ambitious criminals in disparate locations to conspire, and generate enormous sums of money, something that likely would have been impossible only twenty years ago. In contrast, a law enforcement operation to break up an enterprise like AlphaBay requires high-level coordination between multiple law enforcement organizations across different international jurisdictions, all running up hill, trying to identify a small number of individuals who all go through great efforts to remain anonymous. In simple terms, it is much easier and cheaper for a small number of criminals to set up something like AlphaBay, than it is for global law enforcement agencies to tear it down. This means that the moment a site like AlphaBay is taken down, competitors will likely pop up to fill the void, which is apparently exactly what happened.
There are the classic black market items for sale on the Dark Web, such as drugs, guns, and child pornography, but the flexibility and anonymity of the dark web has also created a forum for transactions in new forms of contraband, such as sensitive personal information, classified or otherwise sensitive government documents, and human beings. In the summer of 2017, a twenty year old British woman was kidnapped and drugged while on vacation in Milan, and auctioned off, presumably as a slave, on the dark web. The group that perpetrated the kidnapping, “Black Death”, was known to the media since at least 2015, but some sources believed at the time that Black Death was a hoax. Two years later, it became clear that Black Death is not only an unfortunate reality, but that it is entirely possible that there are scores of other less fortunate victims of human trafficking facilitated by the Dark Web that have gotten no attention at all from law enforcement, or the press.
The Rise of the Global Far-Right
The quality of Trump’s relationship with a foreign leader seems to turn on whether or not that leader can be characterized as far-right. Vladimir Putin, Kim Jong-un, Recep Erdoğan, and Rodrigo Duterte all seem to score high marks from Trump. In contrast, Trump is hostile toward democratic leaders such as Angela Merkel, Emmanuel Macron, and Theresa May. Though his relationship with China is generally adversarial, his initial relationship with Kim Jung-un also began on very shaky grounds, yet ended in bromance. So perhaps this is merely the opening act of what will eventually turn into a courtship dance between Trump and Xi Jinping. Trump’s reaffirmation of the U.S.’s commitment to Israel comes at a strange time for the state of Israel and its people, as Israel has itself been increasingly welcoming of far-right, Eastern European politicians.
Though the history has long left the headlines, the Italian far-right was believed to be behind much of the terrorism that took place there during the 1980’s. Behind Italy’s far right, however, were criminal and quasi-criminal organizations, such as Propaganda Due, who sought to use the resultant political upheaval and popular outrage to launch the political careers of their own members, including Silvio Berlusconi. In the end, while these groups may very well have had a political vision (they were purportedly fascist, anti-communists), the means by which they achieved their ends was to foment political discord using terrorism, and then offer up their own members as political candidates to “solve” the very problems they had created in the first instance.
On the economic front, these groups made use of a sophisticated mix of corporate takeovers, financial crimes, and brutality to secure control of major corporations across Europe. (“God’s Bankers” is a thoroughly researched, nearly scholarly work, on the history of the Vatican Bank, which includes a detailed history of the rise of Propaganda Due). The end result is that a small number of criminal and quasi-criminal actors with deep ties to the Italian state, Italian intelligence, and the Vatican Bank, ended up controlling significant swathes of the Italian economy, and political system, causing several financial disasters along the way, including the collapse of an American bank, the Franklin National Bank. This brand of high-level, highly-organized crime has almost certainly contributed to the present Italian state, which is notorious for crippling dysfunction, corruption, and a preposterous justice system – all of which can now fairly be said of the U.S. government.
Taking the rise of Propaganda Due in Italy as a case study, it is entirely possible that the hands behind the current, global rise of the far right have no genuine political motivation whatsoever, but are instead primarily economic actors, interested only in dysfunctional, weak political states. Weak states, whether through outright corruption, or indifference, allow quasi-criminal organizations like Propaganda Due to carry on with lower boundaries to action. These “men of action”, as the members of Propaganda Due refer to each other, find unfettered commercial environments more conducive to their style of doing business.
You don’t need a tinfoil hat to argue that something similar has been gradually taking place in the U.S over the last thirty years. In this view, Trump’s improbable presidential victory is the climax of a slow-growing economic and political infection, brought about by unchecked flows of international capital, regulatory indifference, and the rise of corruption globally, all of which have now set in motion the possible collapse of the post war world order, and the rise of what is shaping up to be a new world order in which a handful of strongmen dominate the headlines, spending little time on substance, and lots of time massaging each other’s egos.
There is a lot of discussion as to who is responsible for all of this, and it is of course entirely possible that no one is responsible, and that the rise of the global far-right is simply the product of uncoordinated demographic, political, and economic forces. Nonetheless, the obvious culprit is the Russian state: they have both the means and the motive, as the far-right candidates that have popped up in the U.S. and Europe are universally anti-globalist, protectionists, creating the risk of a power vacuum if western democracies truly abandon the current world order, which Russia, and possibly China, would be happy to fill. But it is looking increasingly likely that if the Russians are responsible, then they didn’t act alone, and instead had the help of far-right extremists, globally. This is not to say that the same individuals that were responsible for the rise of the present Italian mafia-state are also responsible for the rise of Donald Trump. That said, Donald Trump and Silvio Berlusconi are, coincidentally, remarkably similar people: both had careers in the media prior to public office; both have rather unabashed ties to organized crime; both have been involved in sex scandals; and, bizarrely, both have signature, rather unusual tans.
Recent events suggest that there is at least superficial evidence of a connection between the far-right in the U.S., and the Russian state. And there is an obvious connection between the far-right, and gun violence, police brutality, and hate crimes, all of which are politically toxic subjects, that are undermining the effectiveness of politicians on both sides of the political spectrum, as voters become increasingly entrenched, focusing on polarizing, hot-button issues, rather than the comparatively boring, but equally important issues of financial regulation, education, trade policy, and the economic and fiscal soundness of the U.S. generally.
If the rise of the global far-right is deliberate, perhaps as designed by the Russian state to expand the sphere of Russian influence further into continental Europe, and beyond, then the same strategy employed by Propaganda Due in Italy during the 1980’s and 1990’s could be being employed in the U.S., and in western democracies generally: foment political dysfunction on both sides of the political spectrum, for example, by sponsoring terrorist activities, and in general by inciting violence (e.g., Donald Trump’s thinly veiled endorsement of police brutality), in order to poison the well of political discourse, destroy the current political order, and eventually, run an outsider candidate, like Trump, as the “solution” to those very problems.

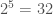


![[\frac{1}{8} ( (21 - 1)^2 + (15 - 2)^2 + (11 -3)^2 + (10 - 5)^2 + (10 - 5)^2 + (11 -3)^2 + (15 - 2)^2 + (21 - 1)^2 )]^{\frac{1}{2}},](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7B1%7D%7B8%7D+%28+%2821+-+1%29%5E2+%2B+%2815+-+2%29%5E2+%2B+%2811+-3%29%5E2+%2B+%2810+-+5%29%5E2+%2B+%2810+-+5%29%5E2+%2B+%2811+-3%29%5E2+%2B+%2815+-+2%29%5E2+%2B+%2821+-+1%29%5E2+%29%5D%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D%2C&bg=ffffff&fg=444444&s=0&c=20201002)



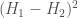


 .
. ,
,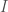 is the optimal code length (measured in bits) of a signal with a probability of p. In this particular case, the ultimate goal is to take an RGB color vector, map it to a probability, and from that, generate a code length using the equation above that we will treat as the information content of the color represented by the RGB vector (see the posts below for more on this approach).
is the optimal code length (measured in bits) of a signal with a probability of p. In this particular case, the ultimate goal is to take an RGB color vector, map it to a probability, and from that, generate a code length using the equation above that we will treat as the information content of the color represented by the RGB vector (see the posts below for more on this approach). that can be easily interpreted (at least mathematically) as a probability. But upon examination, we’ll see that this approach is unsatisfying from a theoretical perspective.
that can be easily interpreted (at least mathematically) as a probability. But upon examination, we’ll see that this approach is unsatisfying from a theoretical perspective. is measure of luminosity that we intend to map to a probability. Luminosity is an objective unit of measurement that does not depend upon its source. As a result, the probability we assign to x should similarly not depend upon the particular source we’re making use of, if we want our method to be objective. That is, a particular level of luminosity should be associated with the same probability regardless of the source that is generating it.
is measure of luminosity that we intend to map to a probability. Luminosity is an objective unit of measurement that does not depend upon its source. As a result, the probability we assign to x should similarly not depend upon the particular source we’re making use of, if we want our method to be objective. That is, a particular level of luminosity should be associated with the same probability regardless of the source that is generating it.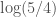 . Now imagine that we have a group of 10 identical light bulbs bundled together. On this device, using 4 of the lights produces a probability of 4/10, and a code length of
. Now imagine that we have a group of 10 identical light bulbs bundled together. On this device, using 4 of the lights produces a probability of 4/10, and a code length of  . In both cases, the luminosity generated would be the same, since in both cases, exactly 4 lights are on. This implies that, as a general matter, if we use this approach, our code lengths will depend upon the particular light source used, and will, therefore, not be an objective mapping from luminosity to probability.
. In both cases, the luminosity generated would be the same, since in both cases, exactly 4 lights are on. This implies that, as a general matter, if we use this approach, our code lengths will depend upon the particular light source used, and will, therefore, not be an objective mapping from luminosity to probability.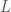 should be given by,
should be given by, ,
, is a constant that represents the length of the code for perceiving light.
is a constant that represents the length of the code for perceiving light. is not the information content of a Shannon code. Instead,
is not the information content of a Shannon code. Instead,  .
. (ignoring the constant term
(ignoring the constant term  back into Shannon’s original equation, we obtain the following:
back into Shannon’s original equation, we obtain the following: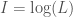 .
.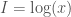 .
.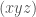 . The total luminosity of the vector is simply
. The total luminosity of the vector is simply 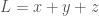 . As a result, we can construct a distribution of luminosity given by,
. As a result, we can construct a distribution of luminosity given by, .
.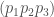 , which will give us a measure of the diffusion of the luminosity across the three channels. The maximum diffusion occurs when each channel has an equal amount of luminosity, which will produce no color at all, and scale from black to white, suggesting that color itself is the perceptual result of asymmetry in the distribution of information across wavelengths of light. In short, a high entropy color contains very little color information, and a low entropy color contains a lot of color information.
, which will give us a measure of the diffusion of the luminosity across the three channels. The maximum diffusion occurs when each channel has an equal amount of luminosity, which will produce no color at all, and scale from black to white, suggesting that color itself is the perceptual result of asymmetry in the distribution of information across wavelengths of light. In short, a high entropy color contains very little color information, and a low entropy color contains a lot of color information. as follows:
as follows: ,
, ,
, and
and 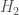 are the respective entropies of
are the respective entropies of  .
.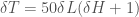 .
.

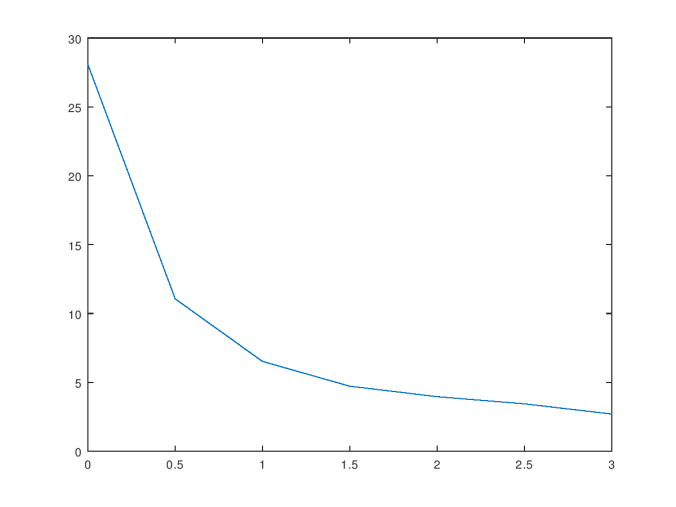
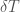 . As you can see, the colors become more similar as we traverse the color bar from left to right, despite the fact that their distances in Euclidean space are constant.
. As you can see, the colors become more similar as we traverse the color bar from left to right, despite the fact that their distances in Euclidean space are constant.

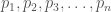 , all purportedly informing us at to the probability of the same event, then we can assign weights to each probability that reflect how “unusual” the information content of the probability itself is in the context of the other probabilities. We begin by taking the logarithm of the reciprocal of each probability, log(1/pi), which gives us the optimal code length for a signal with a probability of pi. We’re not interested in encoding anything, but instead using the code length associated with a probability to measure the information contained in the data that generated the probability in the first instance. This will produce a set of code lengths for each probability
, all purportedly informing us at to the probability of the same event, then we can assign weights to each probability that reflect how “unusual” the information content of the probability itself is in the context of the other probabilities. We begin by taking the logarithm of the reciprocal of each probability, log(1/pi), which gives us the optimal code length for a signal with a probability of pi. We’re not interested in encoding anything, but instead using the code length associated with a probability to measure the information contained in the data that generated the probability in the first instance. This will produce a set of code lengths for each probability  , with lower probabilities having longer code lengths than higher probabilities. We then calculate the average code length over the entire set, u. This is our average information content, from which we will determine how “unusual” a probability is, ultimately generating the weight we’ll assign to the probability. In short, if a probability was generated by an unusually large, or unusually small, amount of information relative to the average amount of information, then we’re going to assign it a larger weight.
, with lower probabilities having longer code lengths than higher probabilities. We then calculate the average code length over the entire set, u. This is our average information content, from which we will determine how “unusual” a probability is, ultimately generating the weight we’ll assign to the probability. In short, if a probability was generated by an unusually large, or unusually small, amount of information relative to the average amount of information, then we’re going to assign it a larger weight.
 ,
,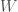 is the sum over all weights.
is the sum over all weights.






