In this article, I’m going to introduce a set of algorithms that can form categorizations on, and predict, discrete data comprised of sets. Their efficiency appears to be unprecedented: running on an iMac, they categorized a dataset of 200,000 vectors, with a dimension of 100 items per vector, in 13 seconds, with 100% accuracy.
I’m in the process of looking for a more formal dataset (e.g., Netflix preferences) to test them on, but nonetheless, using my own datasets, the results are impressive.
The code and training data is available on my researchgate blog.
There’s already another algorithm in my code archive that can form categorizations on datasets that consist of discrete sets, (see, “optimize_categories_intersection_N”). In terms of how it operates, this “intersection algorithm” is no different than the Euclidean algorithm that I introduced in my main research paper on AI, but the intersection algorithm uses discrete set intersection, rather than the Euclidean norm operator, to compare the difference between two elements of a dataset. That is, the Euclidean algorithm assumes the dataset is comprised of vectors, and so it compares two elements by taking the norm of the difference between those two elements. In contrast, the intersection algorithm compares two elements by treating each element as a set, and taking the intersection of those two sets. For example, if 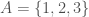 and
and  , then the “distance” measure on those two sets would be
, then the “distance” measure on those two sets would be 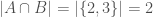 .
.
However, the “optimize_categories_intersection_N” algorithm makes use of a novel form of intersection that I’ve developed called the  -intersection operator that allows for the intersection between sets that contain vectors that are close in value, as opposed to exactly the same symbol. So, for example, the -intersection operator allows us to calculate the intersection between sets
-intersection operator that allows for the intersection between sets that contain vectors that are close in value, as opposed to exactly the same symbol. So, for example, the -intersection operator allows us to calculate the intersection between sets 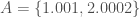 and
and  . If
. If  , then
, then 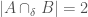 , since
, since  and
and 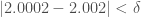 . I developed this operator in the context of color processing, where you might want to take the intersection count between two sets of colors, and say close enough is good enough to constitute a match. For an explanation of how we determine the appropriate value of , see my research note on vectorized image partitioning.
. I developed this operator in the context of color processing, where you might want to take the intersection count between two sets of colors, and say close enough is good enough to constitute a match. For an explanation of how we determine the appropriate value of , see my research note on vectorized image partitioning.
In this article, I’m going to present an otherwise identical categorization algorithm that makes use of ordinary intersection. But unlike the vectorized implementation for the -intersection operator, which I’m quite proud of, the implementation of the intersection operator used in the algorithm I’ll present in this note is trivial and almost certainly widely used, which I’ll nonetheless explain below. As a result, in terms of code, there’s really nothing new in this algorithm when compared to the original categorization and prediction algorithms that I discuss in my main research paper on AI.
However, as a theoretical matter, using the intersection operator creates a completely different measure on the dataset when compared to Euclidean distance, since in Euclidean space, two elements are similar if they’re near each other when represented as points, which implies that the norm of their difference will be small. In contrast, if two sets are similar, then they have a lot of elements in common, which will produce a large intersection count. So even though the Euclidean categorization algorithm and intersection algorithm both operate in the exact same manner, using almost identical code, as a theoretical matter, the intersection algorithm is worth discussing, since it generates some interesting mathematics if we think about the intersection operator as a measure of similarity, or distance, on sets.
Moreover, because of the way these algorithms work, we need to have an expectation value for the intersection count between any two sets. We can of course actually calculate the intersection count between every pair of sets in a given dataset and take the average, but this requires 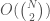 calculations, where
calculations, where  is the number of items in the dataset. The calculation of ordinary intersection can be vectorized trivially, so this is by no means intractable. But, using set theory, we can approximate this number using
is the number of items in the dataset. The calculation of ordinary intersection can be vectorized trivially, so this is by no means intractable. But, using set theory, we can approximate this number using  calculations, which on a low-end device, could mean the difference between an algorithm that runs in a few seconds, and one that runs in a few minutes.
calculations, which on a low-end device, could mean the difference between an algorithm that runs in a few seconds, and one that runs in a few minutes.
Measuring the Difference Between Sets
There is no obvious geometric space in which we can visualize sets that would allow us to say, for example, that two sets are “close” to each other. This implies that the ordinary intuition for categorization, which comes from clustering points that are near each other in space, doesn’t work for categorizing sets. Instead, the intersection algorithm relies upon the intersection count to measure similarity between sets, with no notions of distance at all.
Consider a dataset that consists of consumer purchases at a local supermarket, where each element of the dataset represents the items purchased by a particular consumer. This type of data doesn’t need a location in Euclidean space to be represented. Instead, all we need is a set of distinct but otherwise arbitrary symbols that are sufficient in number to represent the items in question. So if the supermarket sells  items, then we could use the names of the actual products (assuming they’re distinct), the numbers
items, then we could use the names of the actual products (assuming they’re distinct), the numbers  through , the letters
through , the letters  through
through  ,
,  bits, or any other set of distinct symbols, or any other system that can be in distinct states.
bits, or any other set of distinct symbols, or any other system that can be in distinct states.
Assume that one of the elements is 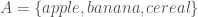 . Any dataset that consists of sets like would be a family of sets, and as a result, we can compare elements within the dataset using the set intersection operator. For example, if
. Any dataset that consists of sets like would be a family of sets, and as a result, we can compare elements within the dataset using the set intersection operator. For example, if  , then
, then  , whereas if
, whereas if  , then
, then  , and so we can reasonably say that and
, and so we can reasonably say that and  are more similar to each other than and
are more similar to each other than and  . In general, the larger the intersection count is between two sets, the more similar the two sets are.
. In general, the larger the intersection count is between two sets, the more similar the two sets are.
If a dataset consists of individual sets, each of which could contain any one of  items, then we can represent the dataset as a binary matrix of rows, and columns, where if entry
items, then we can represent the dataset as a binary matrix of rows, and columns, where if entry  , then set
, then set  contains item
contains item  , and otherwise, the entries are
, and otherwise, the entries are  .
.
We can then calculate the union of any two sets by simply taking the sum of their rows, and testing which entries are greater than zero. Similarly, the intersection is simply the product of corresponding entries. So if  and
and  , and there are
, and there are 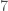 seven items in the dataset, then we would represent as the row vector
seven items in the dataset, then we would represent as the row vector  and as the row vector
and as the row vector  .
.
We can then calculate their union as,



Similarly, we can calculate their intersection as,
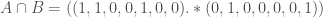
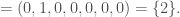
Note that in Matlab, the (.*) operator takes the product between the corresponding entries of two vectors.
Generating Categories
The fundamental approach used in the intersection algorithm is exactly the same as the approach used in all of my algorithms, which is to iterate through different levels of distinction, measuring the entropy of the resultant structure, and then choosing the level of distinction at which the rate of change in entropy is maximized. The intuition for this process is easier to understand in the context of image processing, which actually served as the impetus for all of these algorithms in the first instance.
Consider the image of the red brick wall below, and assume that we want to find the boundaries of the objects in the image. We could accomplish this by identifying significant changes in colors, which in turn requires answering the question of how different two colors have to be in order to distinguish between them. Intuitively, this should depend upon the context of the image. For example, if an image consists solely of very similar colors, then a small change in color could indicate a boundary. In contrast, if an image consists of wildly different colors, then it’s probably only a large change in color that indicates a boundary.

The original image.

The image together with its boundaries.
The solution to this problem, which underlies nearly all of my work in AI, is to pick an initial level of distinction , and then gradually increase that value, measuring the rate of change in the entropy of the structure in question as a function of . The point at which the entropy changes the most is the point at which the level of distinction produces the greatest change in structure. Therefore, my algorithms treat this value of as the level of distinction that is best suited for analyzing an object, or dataset. In the case of boundary detection, we’d increase our level of distinction between colors, and measure the entropy of the structure of the boundaries as a function of our level of distinction . As we iterate, there will be a point where the complexity of the boundaries “pops”, causing a spike in entropy, and it is at this value of that the boundary detection algorithm effectively terminates.
In the case of the intersection algorithm, the goal is to generate categories of sets, grouping together sets that are sufficiently similar to warrant co-categorization. Further, our measure is an intersection count, so rather than asking whether the difference between two sets is less than some , we will instead ask whether the intersection count between two sets is at least . That is, the question is restated as whether two sets have enough elements in common to warrant co-categorization.
The method used by the intersection algorithm is otherwise the same as the Euclidean algorithm, in that it picks an initial anchor set from the dataset, and then iterates through the entire dataset, testing whether the intersection count between each set and that anchor set is at least . If the intersection count between a given set and the anchor set is at least , then the set in question is added to the category associated with that anchor set. In short, if a given set has at least elements in common with the anchor set of a category, then we add that set to the category. We do this until all sets have been assigned to exactly one category, test the entropy of the resultant categorization, and then repeat this process for a new and increased minimum intersection value , selecting the categorization associated with the value of that produces the greatest change in entropy.
The Expected Set
We will of course need to determine the range over which the values of iterate. The Euclidean algorithm uses a function of the standard deviation of the dataset as the maximum , and the minimum is the maximum divided by the number of iterations. By analogy, I’ve used the average of the intersection counts over the entire dataset with what I call the expected set, which is a mathematical construct, and not an actual set of elements. This calculation tells us, on average, what the intersection count would be between a given set, and another set that contains a typical collection of elements from the dataset.
For example, assume that the dataset consists of the family of sets 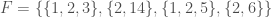 . The union over all of the sets in
. The union over all of the sets in  is
is  , and every item in the union occurs once in the dataset, except for , which occurs twice, and
, and every item in the union occurs once in the dataset, except for , which occurs twice, and  , which occurs four times. If we randomly select a set from , the probability of selecting a set that contains is
, which occurs four times. If we randomly select a set from , the probability of selecting a set that contains is  , since appears in two of the four sets. As a result, if a set contains a , then the expectation value of that item’s contribution to the intersection count between that set and a random set chosen from is . If a set contains a , then the expectation value of that item’s contribution to the intersection count is , since occurs in every set.
, since appears in two of the four sets. As a result, if a set contains a , then the expectation value of that item’s contribution to the intersection count between that set and a random set chosen from is . If a set contains a , then the expectation value of that item’s contribution to the intersection count is , since occurs in every set.
More generally, we can take the intersection between a given set and the union over , and weight each item by the weights just described, where the weight of an item is the number of instances of that item in the dataset, divided by the number of sets in the dataset. Returning to the example above, the union over is  , and the corresponding weights are
, and the corresponding weights are  . The intersection count between
. The intersection count between  and the expected set over is the intersection count between and
and the expected set over is the intersection count between and  , as weighted by the elements of
, as weighted by the elements of 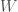 , which is in this case
, which is in this case  .
.
Formally, the intersection count between a given set and the expected set is really a function on the elements generated by the ordinary intersection between that set and the union over the applicable family. For example, first we calculate the intersection between and , which is the set  . Then, we apply a function that maps the elements of that set to the elements of , which are in this case
. Then, we apply a function that maps the elements of that set to the elements of , which are in this case 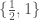 . Then, we take the sum over that set, which I’ve defined as the intersection count between the set in question and the expected set, which is in this case
. Then, we take the sum over that set, which I’ve defined as the intersection count between the set in question and the expected set, which is in this case  .
.
If we actually take the intersection count for every pair of sets in , and then take the average, it comes out to  elements. If we calculate the average intersection with the expected set for each of the four sets, it comes out to
elements. If we calculate the average intersection with the expected set for each of the four sets, it comes out to  elements. On a percentage-wise basis, there is a significant difference between these two values, but nonetheless, this method allows us to generate a reasonable approximation of the average intersection count between every pair of elements with only calculations (note that we can generate the union by taking the sum over the rows of the entire dataset, which requires calculations).
elements. On a percentage-wise basis, there is a significant difference between these two values, but nonetheless, this method allows us to generate a reasonable approximation of the average intersection count between every pair of elements with only calculations (note that we can generate the union by taking the sum over the rows of the entire dataset, which requires calculations).
So to summarize, we begin with a dataset comprised of sets, calculate the expected intersection count using the method outlined above (or actually calculate the average intersection), and then iterate from the expected intersection divided by the number of iterations, up to the expected intersection, constructing categories for each value of , and then select the categorization that is the result of the value of that generated the greatest change in the entropy of the categorization.
Predicting Data
The steps outlined above will allow us to categorize data comprised of sets. We can also find the category of best fit for a new input set by testing the intersection count between that input set and each of the anchor sets generated by the categorization algorithm, and then selecting the category corresponding to the anchor set with which the input set had the greatest intersection count. As a practical matter, this would allow us to make predictions given a discrete set that we know to be part of a larger dataset that we’ve already categorized.
Returning to the example above, if we’ve categorized a dataset of prior consumer purchases, and a new set of purchases by a particular consumer fits best in category , then it’s reasonable to conclude that the consumer in question might also, at some future time, consider purchasing the items contained within the other sets in category .
But we can do better, by using the same technique that I used for the Euclidean algorithm, which is to repeatedly reapply the categorization algorithm to each of the categories generated by the first application, which will generate subcategories for each category. We keep doing this until the categorization algorithm no longer finds any further opportunities for subdivision. This process will generate a tree of subcategories, where the depth represents the number of times the categorization algorithm was applied.
We can then attempt to place a new input set into the tree, and the advantage of this approach is that the subcategories are by definition smaller than the categories within the top level categorization, which will allow us to search through a larger number of smaller categories for a match, thereby generating more accurate predictions. Because a match is determined by the intersection count, and the intersection operator is vectorized, this can be done quickly in at most  calculations, where is the number of categories in the tree, which is generally a low multiple of , the number of items in the dataset.
calculations, where is the number of categories in the tree, which is generally a low multiple of , the number of items in the dataset.
Note that this method is distinguishable from testing whether the presence of one item in an input set implies that another item is likely to be in the input set (perhaps as a piece of missing information). So for example, if a consumer purchases kale, then perhaps it is the case, that as a general matter, that consumer will also probably purchase quinoa. We could look for correlations like this in a dataset of sets using vectorized processes. Specifically, recall that in this case, each row corresponds to a consumer, and each column corresponds to an item. Each row will contain a sequence of 0/1’s that will indicate what items were purchased by each consumer. We can then find, for example, all the rows where column 1 contains a 1, which corresponds to the set of consumers that purchased item 1. We can easily take the sum over any other column we’d like from that subset of rows, which will tell us how many times a consumer that bought item one also bought some other item. This will allow us to produce a vectorized measure of correlation between items in the dataset.
But that’s not what this prediction algorithm does.
Instead, this prediction algorithm takes a set of consumer purchases, and says, as a general matter, to what category does this consumer belong based upon the entirety of the consumer’s purchases. This will allow us to generate an entire set of predictions, as opposed to testing whether one particular item implies that some other item is likely.
Specifically, if an input set maps to a particular category, then all of the items in that category are reasonable predictions for the input set, and we can of course sort them by frequency of occurrence, and as a general matter, use and present these predictions in a manner that is best suited for the particular application at hand. So, for example, if we know that a particular consumer likes a particular set of musical groups, then we can generate a set of suggestions based upon the entirety of the consumer’s preferences.
We could conceivably take into account the complete profile of a consumer, across food, music, zip code, credit range, political party, etc., and then categorize consumers based upon the entirety of the data that is available about them. We then can form expectation values for any missing information based upon the statistics of the category to which the consumer is mapped by the prediction function.
 seconds per image (on average) from start to finish (including all pre-processing time) to classify the dataset of images below. Note that this is the amount of time it took per image to train the classification algorithm, as opposed to the amount of time it would have taken to classify a new image after the algorithm had already been trained. Like all of my algorithms, these algorithms have a low-degree polynomial runtime.
seconds per image (on average) from start to finish (including all pre-processing time) to classify the dataset of images below. Note that this is the amount of time it took per image to train the classification algorithm, as opposed to the amount of time it would have taken to classify a new image after the algorithm had already been trained. Like all of my algorithms, these algorithms have a low-degree polynomial runtime.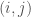 region of the image contains a boundary, then the
region of the image contains a boundary, then the 




 accurate, meaning all categories were perfectly consistent with the hidden classifiers. For the handwritten character dataset, the categorization algorithm had an accuracy of
accurate, meaning all categories were perfectly consistent with the hidden classifiers. For the handwritten character dataset, the categorization algorithm had an accuracy of 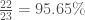 , since exactly
, since exactly 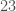 was inconsistent with the hidden classifiers.
was inconsistent with the hidden classifiers.







 . Reading this sequence from left to right, and calculating the difference between adjacent entries, we would place delimiters as follows:
. Reading this sequence from left to right, and calculating the difference between adjacent entries, we would place delimiters as follows: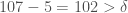 . Because 107 and 210 are categorized together, it must be the case that
. Because 107 and 210 are categorized together, it must be the case that 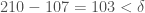 . But obviously, it cannot be the case that
. But obviously, it cannot be the case that 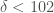 and
and  . Nonetheless, we might need to produce this partition, so as a result, the boundary algorithm makes use of a ratio test, rather than a finite difference test. Specifically, it tests the ratio between the intersection counts of neighboring regions.
. Nonetheless, we might need to produce this partition, so as a result, the boundary algorithm makes use of a ratio test, rather than a finite difference test. Specifically, it tests the ratio between the intersection counts of neighboring regions. , which will cause us to draw a boundary at the right place, between 5 and 107.
, which will cause us to draw a boundary at the right place, between 5 and 107.
 that you can see in the code, which is available in
that you can see in the code, which is available in 





