I thought I had posted something about the logarithm of  , which is something I think about at times, but I can’t seem to find it, so I’ll begin from scratch:
, which is something I think about at times, but I can’t seem to find it, so I’ll begin from scratch:
Lemma 1. The logarithm of is not equal to .
Proof. Assume that  . If we assume that
. If we assume that 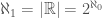 , then it follows that
, then it follows that 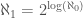 , which leads to a contradiction, since
, which leads to a contradiction, since  .
.
Definitions. As a consequence, I’ve defined a new number,  , that I’ve used in apparently unpublished research to think about the number of bits you’d need to represent a countably infinite system. However, it just dawned on me that you can construct a system that has a number of bits equal to
, that I’ve used in apparently unpublished research to think about the number of bits you’d need to represent a countably infinite system. However, it just dawned on me that you can construct a system that has a number of bits equal to 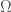 as follows:
as follows:
Assume that a system  is comprised of a countable number of rows, each indexed by the natural numbers, starting with
is comprised of a countable number of rows, each indexed by the natural numbers, starting with  . Now assume that for each row, you have a number of bits equal to the index of the row. So for example, in row , you have bit, which can be in exactly
. Now assume that for each row, you have a number of bits equal to the index of the row. So for example, in row , you have bit, which can be in exactly 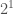 states, and in row
states, and in row  , bits, which can be in exactly
, bits, which can be in exactly  states, etc. However, assume has a tape head, like a UTM, that can move both up and down rows, and left and right, thereby reading or writing to the bits in the row at its current index. So for example, if the head is currently at row , it can move left or right, to access the bits that are in that row. Further, assume that if the head moves either up or down, then all of the bits in every row reset to zero. So this means that once the tape head changes rows, all of the information in the entire system is effectively deleted.
states, etc. However, assume has a tape head, like a UTM, that can move both up and down rows, and left and right, thereby reading or writing to the bits in the row at its current index. So for example, if the head is currently at row , it can move left or right, to access the bits that are in that row. Further, assume that if the head moves either up or down, then all of the bits in every row reset to zero. So this means that once the tape head changes rows, all of the information in the entire system is effectively deleted.
The number of states that can occupy is at least , since it can represent every natural number. However, is distinct from a countably infinite binary string, since changing the row of the tape head causes the entire system to reset, which implies that only a finite number of bits, all within a single row, can ever be used in combination with one another. The number of bits in is therefore unbounded, but not equal to , because they cannot be used in combination with one another, outside of a single row.
Lemma 2. The number of states of cannot be greater than .
Proof. We can assign finite, mutually exclusive subsets of 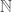 to each row
to each row  of with a cardinality of at least
of with a cardinality of at least 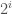 (e.g., use mutually exclusive subsets of powers of primes). Therefore, the number of states of cannot be greater than the number of elements in , which is equal to .
(e.g., use mutually exclusive subsets of powers of primes). Therefore, the number of states of cannot be greater than the number of elements in , which is equal to .
Corollary 3. The number of states of is equal to .
Proof. Every natural number corresponds to at least one state of , which implies that the number of states of is at least . However, Lemma 2 implies that the number of states of cannot be greater than , which implies that they are equal.
Assumption. The number of bits in a system is equal to the logarithm of the number of states of the system.
This is a standard assumption for finite systems, since it implies that a system with  states is equivalent to
states is equivalent to  bits. In this case, it implies that is equivalent to bits, since has exactly states, just like the set of natural numbers itself.
bits. In this case, it implies that is equivalent to bits, since has exactly states, just like the set of natural numbers itself.
Lemma 4. 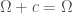 , for all
, for all  .
.
Proof. Assume 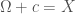 . It follows that
. It follows that  , which implies
, which implies 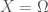 .
.
Corollary 5.  .
.
Proof. This follows immediately from Lemma 4, since there is no such natural number.
Note that 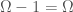 , which in turn implies that we can remove any single row from , without reducing the number of bits in , which is clearly the case.
, which in turn implies that we can remove any single row from , without reducing the number of bits in , which is clearly the case.
Corollary 6.  .
.
Proof. We can assign finite, mutually exclusive subsets of to each row of with a cardinality of at least (e.g., use mutually exclusive subsets of powers of primes). Therefore, the number of bits in cannot be greater than the number of elements in , which is equal to . However, Lemma 1 implies that 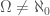 , and therefore, .
, and therefore, .
Corollary 7.  , for all
, for all 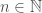 .
.
Proof. For any given , we can always find a row of such that  . Therefore, the number of bits in is greater than
. Therefore, the number of bits in is greater than  , for all .
, for all .
Corollary 8. There is no set  with a cardinality of .
with a cardinality of .
Proof. Assume such a set  exists. Because , for all ,
exists. Because , for all ,  cannot be finite. Because
cannot be finite. Because  , cannot be countable. All subsets of are comprised of either a finite, or countable number of elements, which completes the proof.
, cannot be countable. All subsets of are comprised of either a finite, or countable number of elements, which completes the proof.
So to summarize, the number of bits in is sufficient to represent all natural numbers, and the number of states of is equal to the cardinality of the natural numbers. If we assume as a general matter, that the number of bits in a system is equal to the logarithm of the number of states of the system, then the number of bits in is .
Corollary 9. There is no number of bits  , such that
, such that  , for all .
, for all .
Proof. Assume that such a number exists, and that for some system  , the number of states of is
, the number of states of is  . If
. If  , then , which leads to a contradiction, so it must be the case that
, then , which leads to a contradiction, so it must be the case that  . Because , the number of states of must be less than the number of states of , and so
. Because , the number of states of must be less than the number of states of , and so 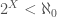 . This implies that we can assign each state of a unique natural number, which in turn implies the existence of a set of natural numbers , such that
. This implies that we can assign each state of a unique natural number, which in turn implies the existence of a set of natural numbers , such that  , for all , and
, for all , and 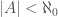 . Since the existence of implies the existence of , which leads to a contradiction, does not exist.
. Since the existence of implies the existence of , which leads to a contradiction, does not exist.
Corollary 10. There is no set such that  .
.
Proof. Assume such a set exists. Since , we can assign each element of a unique natural number, which will in the aggregate generate a set 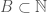 . The existence of
. The existence of  contradicts Corollary 8, which completes the proof.
contradicts Corollary 8, which completes the proof.
This work implies that is the smallest non-finite number, and that it does not correspond to the cardinality of any set.
This in turn implies an elegant theory of number itself:
Begin with a system 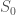 , that is always in the same state
, that is always in the same state 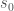 , and assume that the number of states of is , and that the number of bits in is
, and assume that the number of states of is , and that the number of bits in is 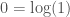 . Now assume the existence of
. Now assume the existence of 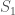 , that is always in the same state
, that is always in the same state 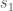 , and that this state is distinct from . Further, assume the existence of some system that can be in either or , and assume that the number of states of is , and that the number of bits in is
, and that this state is distinct from . Further, assume the existence of some system that can be in either or , and assume that the number of states of is , and that the number of bits in is  . If we allow for unbounded instances of to exist in conjunction with one another, then basic counting principles imply the existence of all natural numbers, since a collection of systems, each equivalent to , is in turn equivalent to some binary string.
. If we allow for unbounded instances of to exist in conjunction with one another, then basic counting principles imply the existence of all natural numbers, since a collection of systems, each equivalent to , is in turn equivalent to some binary string.
Note that in this view, the number  always has units of bits, and is never some number of states, just like must always have units of bits, since it does not correspond to the cardinality of any set, or number of states. It suggests the notion that some numbers must necessarily cary particular units, because they can only be derived from one class of mathematical object, that necessarily implies those units. For example, in this view, must always carry units of bits, and can never cary units of states. In contrast, can be either a number of bits, or a number of states.
always has units of bits, and is never some number of states, just like must always have units of bits, since it does not correspond to the cardinality of any set, or number of states. It suggests the notion that some numbers must necessarily cary particular units, because they can only be derived from one class of mathematical object, that necessarily implies those units. For example, in this view, must always carry units of bits, and can never cary units of states. In contrast, can be either a number of bits, or a number of states.
Interestingly, Shannon’s equation implies that the logarithm of the reciprocal of a probability,  has units of bits. The work above implies that the logarithm of some number of states, also has units of bits. Together, this implies that a probability has units of the reciprocal of some number of states,
has units of bits. The work above implies that the logarithm of some number of states, also has units of bits. Together, this implies that a probability has units of the reciprocal of some number of states, 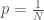 . This is perfectly consistent with a frequentist view of a probability, which would be expressed as some portion of some number of states. Again, all of this work suggests the possibility that numbers have intrinsic units, apart from any physical measurement.
. This is perfectly consistent with a frequentist view of a probability, which would be expressed as some portion of some number of states. Again, all of this work suggests the possibility that numbers have intrinsic units, apart from any physical measurement.
 is Kolmogorov-random, then the Kolmogorov complexity of
is Kolmogorov-random, then the Kolmogorov complexity of  , which is the shortest input to a UTM,
, which is the shortest input to a UTM,  , that will generate
, that will generate  , is equal to
, is equal to  , for some constant
, for some constant  that does not depend upon
that does not depend upon 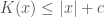 .
.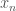 denote the first
denote the first  denote the output of a UTM when given
denote the output of a UTM when given  that can generate the next
that can generate the next 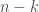 entries of
entries of  entries of
entries of  .
. , we can generate the next
, we can generate the next  on a UTM, using
on a UTM, using  with at most
with at most  bits, it follows that
bits, it follows that 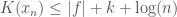 , which implies that,
, which implies that,  . Note that the difference
. Note that the difference 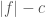 is constant, and because we can, for any fixed value of
is constant, and because we can, for any fixed value of  , where
, where  is the index of some entry within
is the index of some entry within 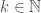 . Because
. Because  , such that
, such that 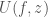 will generate exactly
will generate exactly  , and assume that
, and assume that  . Note that
. Note that 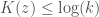 . This implies that
. This implies that 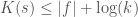 .
.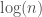 bits. Since there are
bits. Since there are 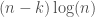 bits.
bits.![K(x_n) \leq K(s) + K(y) + (n - k) \log(n) \leq [|f| + \log(k)] + (n - k) + (n - k) \log(n)](https://s0.wp.com/latex.php?latex=K%28x_n%29+%5Cleq+K%28s%29+%2B+K%28y%29+%2B+%28n+-+k%29+%5Clog%28n%29+%5Cleq+%5B%7Cf%7C+%2B+%5Clog%28k%29%5D+%2B+%28n+-+k%29+%2B+%28n+-+k%29+%5Clog%28n%29&bg=ffffff&fg=444444&s=0&c=20201002) .
. ,
,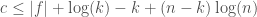 .
.








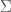 , and that for any
, and that for any  strings. What this says is, the set of possible outcomes never changes, regardless of how many observations you’ve already made. One consequence of this is that you always have the same uncertainty with respect to your next observation, which could produce any one of the signals in
strings. What this says is, the set of possible outcomes never changes, regardless of how many observations you’ve already made. One consequence of this is that you always have the same uncertainty with respect to your next observation, which could produce any one of the signals in  or
or  might seem superficially random, but they’re not, and are instead entirely determined ex ante by a computable process. If a source is truly random, then intuition suggests that eventually, it will evade modeling by a UTM, which implies that with a significantly large enough number of observations, the string of observations generated by the source should approach the complexity of a Kolmogorov random string.
might seem superficially random, but they’re not, and are instead entirely determined ex ante by a computable process. If a source is truly random, then intuition suggests that eventually, it will evade modeling by a UTM, which implies that with a significantly large enough number of observations, the string of observations generated by the source should approach the complexity of a Kolmogorov random string. , and every number of observations
, and every number of observations 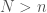 , for which,
, for which, ,
, is the string generated by making
is the string generated by making  . And again, this will cause the platform to wobble, because the front and the back columns on the right will be at different heights at all times until the drop is complete. Now assume instead we deliver simultaneous instructions to both the front and back column on the right. This will produce a uniform set of signals, that consists of exactly one instruction, delivered repeatedly. Therefore, this set of signals has a zero entropy distribution.
. And again, this will cause the platform to wobble, because the front and the back columns on the right will be at different heights at all times until the drop is complete. Now assume instead we deliver simultaneous instructions to both the front and back column on the right. This will produce a uniform set of signals, that consists of exactly one instruction, delivered repeatedly. Therefore, this set of signals has a zero entropy distribution.