I’ve randomly decided to spend some time recording, and this is the result:
Uncategorized
A Note on Potential Energy
Introduction
In my main paper on physics, A Computational Model of Time-Dilation, I presented a theory of gravity that is consistent with the General Theory of Relativity (see Section 4), in that it implies the correct equations for time-dilation due to gravity, despite having no notion of space-time at all. I briefly discussed Potential Energy (see Section 4.2), hoping even then to address it formally in a follow up paper that would include other topics, but the economic pressure to focus on A.I. has led me to spend the vast majority of my time on A.I., not physics. As a result, I’ve decided to informally present my theory of potential energy, below, though I nonetheless plan to address the topic somewhat more formally in the work I’m now starting in earnest on thermodynamics, at the intersection of A.I. and physics.
Pressure
Imagine you have a wooden bookshelf. Even though the bookshelf is not visibly moving, in reality, there is some motion within the wood at very small scales, due to heat and intramolecular forces. Even if you cut into a plank, you still won’t see any motion inside of the wood at our scale of observation, because again, the motion is due to forces that are so small, you can’t see them with your eyes.
Now imagine you place a book on top of the shelf. Gravity will act on the book, and cause it to exert pressure on the surface of the bookshelf –
You know this must be the case, because it’s something you can perceive yourself, by simply picking up the book, and letting it lay in your hand.
Physicists discussing gravity typically ignore this aspect of pressure and focus instead on the notion of potential energy, saying that the book has some quantity of potential energy, because it is in the presence of a gravitational field, that would cause it to fall, but for the bookshelf.
We can instead make perfect physical sense of this set of facts without potential energy by assuming that the book is again actually moving at some very small scale, pushing the surface of the wood down, and in response, the intramolecular forces within the wood, which are now compressed past equilibrium, accelerate the surface of the wood back up, creating an oscillatory motion that is simply not perceptible at our scale of observation. In crude terms, the force of gravity pushes the book and the wood down, and the forces within the wood push the wood and the book back up, creating a faint oscillatory motion.
Note that this set of interactions doesn’t require potential energy at all, since if you push the book off of the shelf, it falls due to gravity, accumulating new kinetic energy. Therefore, the notion of potential energy is not necessary, at least for the purpose of explaining the accelerating effects of gravity.
The term I’ve used to describe this phenomenon is net effective momentum, which is simply the average total vector momentum of a system, over some period of time, or space. Returning to the example above, the net effective momentum of the book on the shelf would be roughly zero over any appreciable amount of time, since for every period of time during which the book moves up, there’s some period of time over which the book moves down, by a roughly equal distance, at roughly the same velocities, in each case, producing an average momentum that is very close to zero.
Now consider a baseball that’s just been hit by a bat –
Initially, the ball will likely be wobbly and distorted, if examined carefully over small periods of time, though its macroscopic velocity will probably stabilize quickly, and therefore, so will its net effective momentum, despite the internal tumult of the ball that certainly exists during its entire flight. The purpose of the net effective momentum is to capture the macroscopic motion of the ball, despite the complexities of the underlying motions.
As it turns out, my entire model of physics is statistical, and assumes that even elementary particles have complex motions, and the notion of net effective momentum is simply a macroscopic version of the definition of velocity that I present in Section 3.3 of my main paper.
VeGa
VeGa – Updated Draft
Updated Deck / Library
I’ve updated my A.I. deck, which you can find here (and attached):
https://www.researchgate.net/publication/346009310_Vectorized_Deep_Learning
I’ve updated my A.I. code library, which you can find here:
Analyzing Classification Consistency
Introduction
Real world data is often observably consistent over small distances. For example, the temperature on the surface of an object is probably going to be roughly the same over distances that are small relative to its total area. Similarly, the average color in an image of a real world object generally doesn’t change much over small distances, other than at its boundaries. Many commonly used datasets are also measurably consistent to some degree, in that classifications do not change over relatively small distances. In a previous article, I noted that if your dataset is what I call, “locally consistent”, which means, informally, that classifications don’t change over some fixed distance, then the accuracy of the nearest neighbor algorithm cannot be exceeded.
In this note, I’ll again present the idea of local consistency, though formally, through a series of lemmas. I’ve also attached code that makes it easy to measure the classification consistency of a dataset, which in turns implies that you can say, ex ante, whether nearest neighbor will in fact be the best the algorithm for the dataset, in terms of accuracy. Finally, because nearest neighbor can be implemented using almost entirely vectorized operations, it would have at worst a linear runtime as a function of the number of rows in the dataset, on a sufficiently parallel machine.
Local Consistency
A dataset 



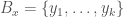




For reference, the nearest neighbor algorithm simply returns the vector within a dataset that has the smallest Euclidean distance from the input vector. Expressed symbolically, if 







Lemma 1. If a dataset
Proof. Assume that the nearest neighbor algorithm is applied to some dataset 

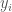


What Lemma 1 says is that the nearest neighbor algorithm will never generate an error when applied to a locally consistent dataset, since the nearest neighbor of an input vector
Corollary 2. A dataset is locally consistent if and only if the nearest neighbor algorithm does not generate any errors.
Proof. Lemma 1 shows that if a dataset 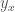


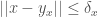
Corollary 3. A dataset is locally consistent around
Proof. Assume that the nearest neighbor algorithm does not generate an error when applied to 

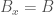

Now assume that 
Clustering
We can analogize the idea of local consistency to geometry, which will create intuitive clusters that occupy some portion of Euclidean space. We say that a dataset 
Lemma 4. A dataset is locally consistent if and only if it is clustered consistently.
Proof. Assume 
Now assume that 
What Lemma 4 says, is that the notion of local consistency is equivalent to an intuitive geometric definition of a cluster that has a single classifier.
Lemma 5. If a dataset 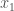
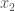

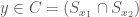
Proof. If the regions bounded by the spheres 



There are three possibilities regarding the classifier of
(1) It is equal to the classifier of
(2) It is equal to the classifier of
(3) It is not equal to the classifiers of
In all three cases, it follows that 

What Lemma 5 says, is that if two clusters overlap as spheres, then their intersecting region contains no vectors from the dataset.
Corollary 6. If
Proof. It follows immediately from Lemma 5, since any such algorithm could simply generate the sphere
You can easily approximate the value of 
Here’s a more formal PDF document that presents the same results:
Vectorized Image Classification (RGB Version)
Following up on my article from yesterday, here’s a full color version that can classify images using almost entirely vectorized processes, and the runtimes are excellent, though I’m still testing it, and going to apply it to a wider set of datasets –
As applied to a simple dataset I made up of three grocery items, a lime, an avocado, and a grapefruit (30 images total, 10 per class), it takes about 1/10 of one second to identify an item with perfect accuracy, which certainly makes it usable as a scanner at an actual grocery, though again, I’m going to test it more, and write a more formal article on the technique.
Below are three sample images, together with representative super-pixel images actually fed to the classifier algorithm.





Here’s the command line code:
Here’s the code that displays the super-pixel images:
Here’s the full image dataset.
Vectorized Nearest Neighbor
I’m working on an image classification algorithm, and I found an extraneous line of code in my nearest neighbor algorithm, which I’ve now reduced to eleven lines of code:
function nearest_neighbors = NN_fully_vectorized(dataset, N)
dataset = dataset(:,1:N); %removes the hidden classifier
num_rows = size(dataset,1);
temp_matrix = repmat(dataset’, [1 1 num_rows]);
ref_dataset = shiftdim(temp_matrix,2);
diff_matrix = sum((dataset.-ref_dataset).^2,2);
zero_indeces = 1:num_rows+1:num_rows*num_rows;
diff_matrix(zero_indeces) = Inf; %sets the zero entries to infinity
[a b] = min(diff_matrix);
nearest_neighbors = reshape(b,[num_rows 1]);endfunction
Vectorized Image Preprocessing
In a previous article, I introduced an algorithm that can quickly partition an image into rectangular regions, and calculate the average color in each region, which would then be used for image classification. When I applied it to the MNIST dataset, I got good results, but there was an apparent ceiling of about 87% accuracy that I couldn’t breach, regardless of how many rows of the dataset I used. My original MNIST preprocessing algorithm had much better results, and the prediction algorithm was the same, which suggests a question –
Why is this one not as good?
And I realized, the answer is, I didn’t get rid of the background of the image, which in the aggregate, ends up generating a significant amount of noise, because it’s not exactly the same in every image, yet it’s a substantial portion of each image, which cumulatively, interfered with the prediction algorithm.
As a solution, I simply nixed every dimension that has a standard deviation of less than the average standard deviation across all dimensions, by setting them to zero. What this says is, if a dimension doesn’t really move much across all rows in a dataset, in the context of image processing, it’s probably background. You can’t always say this is correct, but for the MNIST dataset, it’s obviously true, because the background is in roughly the same place in every image, and roughly equal in luminosity. This implies that the background dimensions should have significantly lower standard deviations than the average across all dimensions. And it turns out, this works quite well, and produces accuracy that is on par with my previous preprocessing algorithm (93.35%, given 2,500 rows). However, the difference is, in this case, this is a general approach that should work for all simple image datasets that have a roughly uniform background, unlike my previous preprocessing algorithm, which was specific to the MNIST dataset.

