I was reading my absolute favorite book on mathematics, Mathematical Problems and Proofs, and it mentions Cantor’s Theorem, that the cardinality of a set is always less than the cardinality of its power set. So for example, the cardinality of  , which is less than
, which is less than  . There is however no proof in that book of the general case, and instead only a proof of the finite case, expressed as a counting argument. I looked up proofs, and all the proofs I could find seem to have the same hole, which I’ll discuss.
. There is however no proof in that book of the general case, and instead only a proof of the finite case, expressed as a counting argument. I looked up proofs, and all the proofs I could find seem to have the same hole, which I’ll discuss.
Let  be a set, and let
be a set, and let  denote the power set of , i.e., the set of all of its subsets. Now assume that
denote the power set of , i.e., the set of all of its subsets. Now assume that  . That is, we are assuming arguendo that the cardinality of is not less than the cardinality of its power set, in contradiction to Cantor’s Theorem. It follows that there must be some function
. That is, we are assuming arguendo that the cardinality of is not less than the cardinality of its power set, in contradiction to Cantor’s Theorem. It follows that there must be some function  such that
such that  is surjective, which means that all elements of are mapped to by , and such a function must exist, because we have assumed that . That is, because , there are enough elements in to map to every element in .
is surjective, which means that all elements of are mapped to by , and such a function must exist, because we have assumed that . That is, because , there are enough elements in to map to every element in .
Now the next step of the proof (at least the few versions I saw this morning) all universally define the set  below, without addressing the possibility that the set is empty, though it’s possible the original proof addresses this case. My issue with this, is that there doesn’t seem to be any difference between an empty set, and a set that is provably non-existent. As such, I don’t think empty sets should be used as the basis of a proof, unless the proof follows only from the non-existence of the set, and other true theorems, true axioms, or additional assumptions (in the case of a line of reasoning being considered arguendo). In this case, proving the set in question is non-empty, changes the scope of the proof, in that it only applies to sets with a cardinality of two or greater. Most importantly, consistent with this, the accepted proof fails in the case of the power set of the empty set, and in the case of the power set of a singleton, because of this hole. This is very serious, the proof is literally wrong, and fails in two cases, that are plainly intended to be covered by the proof.
below, without addressing the possibility that the set is empty, though it’s possible the original proof addresses this case. My issue with this, is that there doesn’t seem to be any difference between an empty set, and a set that is provably non-existent. As such, I don’t think empty sets should be used as the basis of a proof, unless the proof follows only from the non-existence of the set, and other true theorems, true axioms, or additional assumptions (in the case of a line of reasoning being considered arguendo). In this case, proving the set in question is non-empty, changes the scope of the proof, in that it only applies to sets with a cardinality of two or greater. Most importantly, consistent with this, the accepted proof fails in the case of the power set of the empty set, and in the case of the power set of a singleton, because of this hole. This is very serious, the proof is literally wrong, and fails in two cases, that are plainly intended to be covered by the proof.
The Modified Proof
Specifically, proofs of Cantor’s theorem define  . That is, because we know (defined above) must exist, we know that we can define , using . However, it’s possible that is empty, since there might not be any such
. That is, because we know (defined above) must exist, we know that we can define , using . However, it’s possible that is empty, since there might not be any such  . That said, a simple additional step will prove that we can always define
. That said, a simple additional step will prove that we can always define 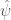 , which will produce a non-empty set
, which will produce a non-empty set  .
.
Assume that is empty and that  . Because
. Because  , there must be
, there must be  , such that
, such that  , and
, and  . Because is surjective, there must be
. Because is surjective, there must be 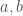 such that
such that  and
and  . If
. If  or
or  , then is non-empty. As such, assume that
, then is non-empty. As such, assume that  and
and  . Now define , such that
. Now define , such that  and
and  , but otherwise
, but otherwise  for
for  . If
. If  and
and  are both singletons, then
are both singletons, then  and
and  . If either is not a singleton (or both are not singletons), then it must be the case that either or , or both. This implies that is not empty. Because this can be done for any surjective function , we are always guaranteed a non-empty set
. If either is not a singleton (or both are not singletons), then it must be the case that either or , or both. This implies that is not empty. Because this can be done for any surjective function , we are always guaranteed a non-empty set  Note that is still surjective.
Note that is still surjective.
Now we can complete the proof as it is usually stated. Because is surjective, there must be some 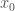 such that
such that  . It must be the case that either
. It must be the case that either  or
or  . If , then fails the criteria for inclusion in , namely
. If , then fails the criteria for inclusion in , namely  , since by definition,
, since by definition,  . If , then satisfies the criteria for inclusion in . In both cases, we have a contradiction. The assumption that implies the existence of , which in turn implies the existence of and , which leads to a contradiction. In order to resolve this contradiction, we must therefore assume instead that
. If , then satisfies the criteria for inclusion in . In both cases, we have a contradiction. The assumption that implies the existence of , which in turn implies the existence of and , which leads to a contradiction. In order to resolve this contradiction, we must therefore assume instead that  , which completes the proof.
, which completes the proof.
The Case of the Empty Set
Now assume that  , and let’s apply the proof above. Generally speaking, we would assume that the power set of the empty set contains one element, namely a set that contains the empty set as a singleton, represented as
, and let’s apply the proof above. Generally speaking, we would assume that the power set of the empty set contains one element, namely a set that contains the empty set as a singleton, represented as  . Assuming we can even define in this case, it must be that
. Assuming we can even define in this case, it must be that  . Because
. Because  , it must be the case that
, it must be the case that  . However, if we want
. However, if we want  , it must be the case that
, it must be the case that  , even though . Therefore,
, even though . Therefore,  , and instead, , and as a result, the proof fails in the case of
, and instead, , and as a result, the proof fails in the case of  since
since  . That is, the accepted proof assumes is contained in the power set, which is just not true in this case, suggesting that there really are problems deriving theorems from empty sets.
. That is, the accepted proof assumes is contained in the power set, which is just not true in this case, suggesting that there really are problems deriving theorems from empty sets.
The Case of a Singleton
Now assume that  , and let’s apply the proof above. The power set of a singleton is generally defined as
, and let’s apply the proof above. The power set of a singleton is generally defined as  . Because the accepted proof does not explicitly define , we are free to define
. Because the accepted proof does not explicitly define , we are free to define  . Because
. Because  , . As noted above, , and therefore,
, . As noted above, , and therefore,  . Again, the accepted proof fails.
. Again, the accepted proof fails.
Because the accepted proof fails in two cases where is empty, my axiom above requiring sets to be non-empty in order to derive theorems, must be true. Nothing else above within the proof is subject to meaningful criticism. Again, I have no idea whether Cantor’s original proof addressed these points, but it’s surprising that no one has bothered to apply these proofs to the case of the empty set and a singleton, which would make it clear it doesn’t work.







![\theta_i \in [0,1]](https://s0.wp.com/latex.php?latex=%5Ctheta_i+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002)

![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002)



 , I’m not encoding or representing anything, and I am instead referencing something that is in your memory as a reader, thereby conjuring a concept with which you’re already familiar, that cannot be expressed physically in finite time.
, I’m not encoding or representing anything, and I am instead referencing something that is in your memory as a reader, thereby conjuring a concept with which you’re already familiar, that cannot be expressed physically in finite time.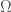 , which is defined as the logarithm of
, which is defined as the logarithm of  . You can read more about it in
. You can read more about it in 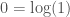 , which satisfies our intuition, that zero represents no substance. Further, in this case, zero is the amount of information contained in a system that has exactly one state. This is plainly true, since a system that never changes cannot meaningfully store information, and instead simply exists. Similarly,
, which satisfies our intuition, that zero represents no substance. Further, in this case, zero is the amount of information contained in a system that has exactly one state. This is plainly true, since a system that never changes cannot meaningfully store information, and instead simply exists. Similarly,  is defined, because that is simply the product
is defined, because that is simply the product  , taken a countable number of times. Basic assumptions of arithmetic imply the following inequality:
, taken a countable number of times. Basic assumptions of arithmetic imply the following inequality: .
. , it must be the case that
, it must be the case that  .
. .
. such that
such that  , for all
, for all 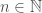 and
and  . Therefore,
. Therefore,  does not exist. As a result, we learn nothing from taking the logarithm, since
does not exist. As a result, we learn nothing from taking the logarithm, since  .
. .
. , for all
, for all  is not defined. In contrast,
is not defined. In contrast,  is just the number of bits contained in two machines, and more generally,
is just the number of bits contained in two machines, and more generally,  is simply the number of bits contained in
is simply the number of bits contained in  machines. It’s not clear how to think about a collection of machines
machines. It’s not clear how to think about a collection of machines 