In my model of physics, energy is quantized (see Section 2 of this paper), and moreover, energy is the fundamental underlying substance of all things. This gives photons real substance, since they’re comprised of nothing other than energy that happens to be moving. In contrast, mass is energy that happens to be stationary, in the absence of kinetic energy, which is simply light attached to mass, that causes the mass to move. This is obviously not inconsistent with Einstein’s celebrated mass-energy equivalence, but is instead more abstract, and includes and implies that mass and light are interchangeable and equivalent.
I also showed that from a set of assumptions that are completely unrelated to relativity, and that have nothing to do with time directly, and are instead rooted in combinatorics and information theory, you end up with the correct equations of physics, for everything, for time-dilation, gravity, charge, magnetism, and I’ve even tackled a significant amount of quantum mechanics as well (see this book, generally).
I spend most of my time now thinking about thermodynamics, and A.I., because the two are in my opinion deeply interconnected, and have commercial applications to drone technology, though I still think about theoretical physics, and in particular, the fact that light will apparently travel indefinitely in a vacuum. Related, in my opinion, is the fact that gravity cannot be insulated against. Both suggest an underlying mechanic that is inexhaustible, by nature. Moreover, mass-energy equivalence plainly demonstrates the connections between mass and light, which I think I’ve likely exhausted as a topic in the first paper I linked to above. However, I did not address the connections between the apparently perpetual nature of the motion of light in a vacuum, and the apparently inexhaustible acceleration provided by gravity.
I now think I have an explanation, which is as follows:
Whatever substance it is that allows for the indefinite motion of a photon is equivalent to the force carrier of gravity, though in a different state. Whatever this substance is, in the case of a photon, it is withheld by the photon, and in the case of mass, expelled by the mass, which we would therefore view as the force carrier of gravity.
This model effectively assumes that the force carrier of gravity also has two states, just like energy itself, which is either kinetic or massive. In the case of a photon, we have a force carrier that causes the photon itself to move, indefinitely. In the case of a mass, we have an expelled, independently moving force carrier for gravity, that causes unbounded acceleration in other systems (in that it cannot be insulated against or exhausted). In the jargon of my model, position is itself a code, as is what I call the “state” of a particle, which determines all of its properties. For example, the code for an electron is distinct from the code for a tau lepton (see Section 3 of this paper). This actually works quite well at the quantum level, where you have bosons that can literally change the properties of another particle altogether, which my model would view as an exchange of code, which is mathematically equivalent to momentum (see Equation 10 of this paper).
In this view, the gravitational force-carrier when acting on a photon changes the position code of the photon, indefinitely, causing it to move, indefinitely. Because code and momentum are equivalent in my model, this would be an exchange of momentum from the force carrier to the photon, that causes it to change position, which is, again, defined by a code. This view implies that the locomotive force of movement itself is due to this force carrier changing a code within the photon, which causes the appearance of motion over time. In the case of a mass emitting gravity, this force carrier would instead change the state of some exogenous particle, changing its properties, in this case its momentum and total energy.
There is a question of what happens to this force carrier, assuming it exists, when light travels through a medium –
Light certainly slows down in a medium, and light certainly changes behavior in some mediums, both of which suggest the possibility of perhaps separating light from whatever this force carrier is. If possible, then perhaps it could be applied to other systems, causing motion in those systems. Obviously, this would be a very valuable tool, if it exists, and further, assuming it can be separated from light, and further manipulated. Moreover, as a matter theory, it implies a conservation between mass and energy, in that mass emits gravity, whereas a photon does not, and this fills the gap.
You can quibble about this a bit, because the force carrier for gravity is emitted indefinitely, presumably separately, resulting in a large number of force carriers over time. In contrast, you arguably don’t need that to be the case to cause the position of a photon to change. However, because the accelerating power of gravity cannot be exhausted, gravity cannot cary finite momentum. Therefore, one such force carrier carries the same amount of momentum as any finite number of force carriers, and so, there is a conservation of momentum between the photon state of this carrier and the mass state of this carrier.

 . Then, simply take the inverse log of
. Then, simply take the inverse log of 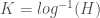 , then you would partition the space in question into
, then you would partition the space in question into  equally sized regions, which would require
equally sized regions, which would require  regions per dimension, where
regions per dimension, where  is the dimension of the space in question.
is the dimension of the space in question.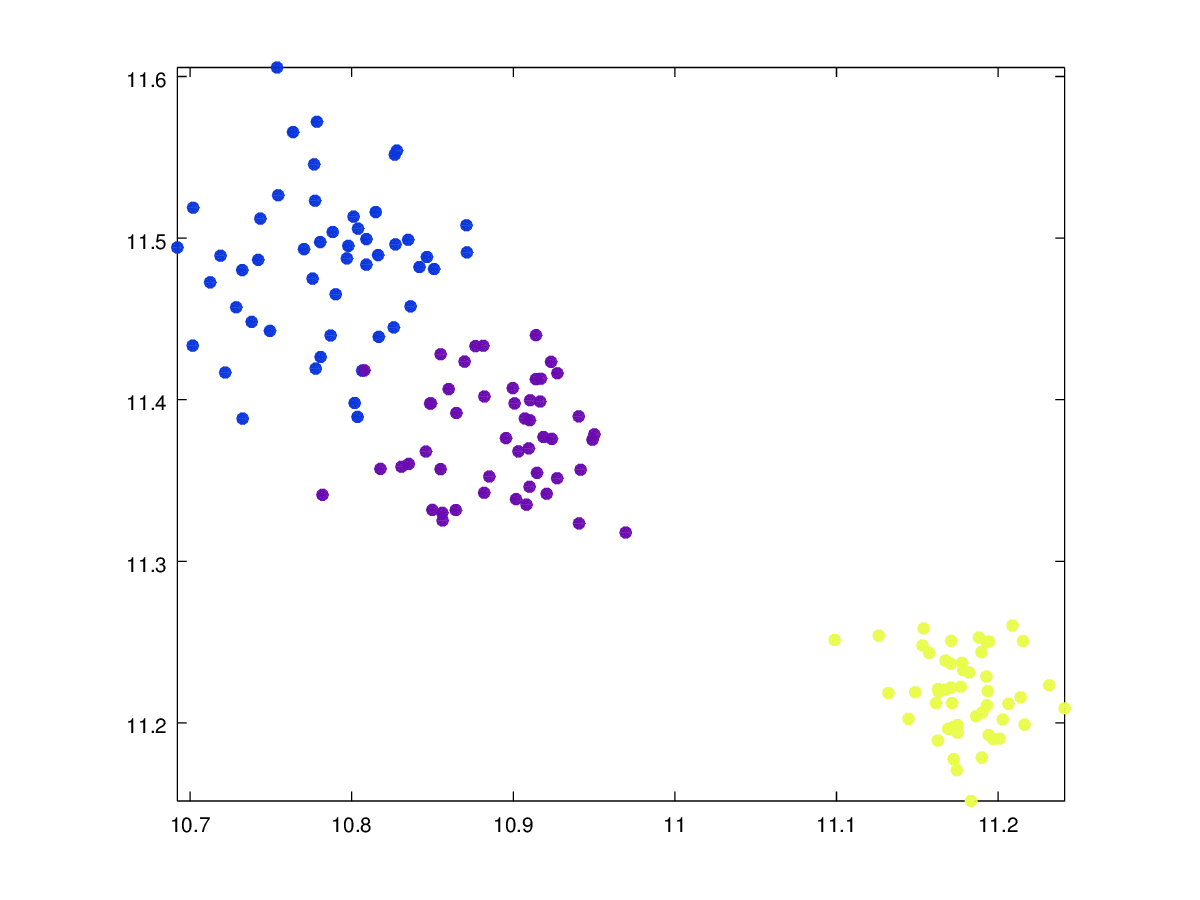
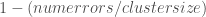 ,
, .
. , and label the vertices with their classifiers. Now, for each such path in
, and label the vertices with their classifiers. Now, for each such path in  and
and  are both vertices in some path
are both vertices in some path  within the set
within the set 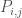 . Assume that the classifier of
. Assume that the classifier of  and that the classifier of
and that the classifier of  , for
, for  . It follows that as we traverse
. It follows that as we traverse  be the edge where this change occurs. Note that it could be the case that
be the edge where this change occurs. Note that it could be the case that 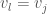 . Because
. Because  is the nearest neighbor of
is the nearest neighbor of  , and by definition the classifiers of
, and by definition the classifiers of 