Here’s a link to an updated zip of all of my algorithms, as of today, of course subject to my Copyright Policy.
Uncategorized
Black Tree AutoML – MacOS
I’ve completed an initial free version of my software for MacOS, and it’s a stand-alone executable you can download below, together with a few example datasets. Here’s a video that shows you how to use the software, but it’s really straightforward:
Download Executable (click on the ellipsis on the far right of the screen, and select “Download”).
Black Tree AutoML Kick Starter Campaign
Just following up, I’ve already raised some money through my Kick Starter campaign, but as this is my primary source of fundraising for the time being, more is obviously better:
As a reminder, there are four levels of funding:
1. $5
2. $25
3. $100
4. $500
Each entitles you to a commercial license to use increasingly sophisticated versions of my software.
Feel free to forward this to anyone that you think might be interested, as these are deeply discounted licenses to use software, which is already only a small fraction of the cost of competing products, that are again, demonstrably inferior.
Regards,
Charles
Black Tree AutoML Kickstarter Campaign
Dear Readers,
I’ve decided to fund my A.I. venture using Kickstarter, as it is the most attractive avenue to keep things moving, since it effectively allows me to sell discounted versions of my software upfront, and keep whatever proceeds I raise:
https://www.kickstarter.com/projects/blacktreeautoml/black-tree-automatic-machine-learning
There are four levels of funding:
1. $5
2. $25
3. $100
4. $500
Each gives one person a life-time commercial license to use increasingly sophisticated versions of my software, that I plan to charge monthly for once the software is released on Apple’s App Store.
The idea is to completely democratize access to A.I., by taking the software to market using the Apple App Store, offering it at a small fraction of what competing products charge, the idea being that a global audience that pays a small sum per month is more profitable than marketing only to enterprise clients that pay large sums of money –
The plan is to sell the McDonalds of A.I., for $5 or $50 per month, depending on what you need.
There’s a video on the Kickstarter page that demonstrates the software, but at a high-level, it is, as far as I know, the most efficient machine learning software on Earth, and incomparably more efficient than Neural Networks, accomplishing in seconds what takes a Neural Network hours. It is also fully autonomous, so you don’t need a data scientist to use it –
Anyone can use it, as it’s point and click.
This will allow small and large businesses alike to make use of cutting-edge A.I. that could help manage inventory, predict sales, predict customer behavior, etc.
I’ve also shown that it’s capable of diagnosing diseases using medical imaging, such as brain MRI’s, again with the same or better accuracy as a neural network:
https://derivativedribble.wordpress.com/2021/09/23/confidence-based-prediction/
Because it can run quickly on a laptop, this will allow for medical care to be delivered in parts of the world where it is otherwise unavailable, and at some point, I plan to offer a free version for exactly this purpose.
Your support is appreciated, and it’s really going to make a difference.
Best,
Charles
VeGa – Current Draft
Here’s another draft of VeGa.
Updated Pitch Deck
Though my paper Vectorized Deep Learning goes through all of the core results for basic applications of my algorithms, it’s not really a deck and is instead a summary scientific paper, so I’ve put together a brief deck I plan to turn into a movie shortly, where I’ll demo my software.
Enjoy!
Information, Knowledge, and Uncertainty
VeGa – Current Draft
Here’s an updated draft of VeGa:
Matrix / A.I. Library for Mac OS Swift
This is still a work in progress, but it contains a lot of functions that I found to be missing from Swift for doing machine learning, and using matrices in general.
Note this is of course subject to my copyright policy, and cannot be used for commercial purposes.
The actual commercial version of my core A.I. library should be ready in about a month, as this is going much faster than I thought it would.
I’ve also included a basic main file that shows you how to read a dataset, run nearest neighbor, manipulate vectors, and generate clusters. It’s the same exact algorithms you’ll find in my Octave library, the only difference being it’s written in Swift, which is not vectorized, but has the advantage of publishing to the Apple Store, and that’s the only reason I’m doing this, since I don’t really need a GUI for this audience.
Confidence-Based Prediction
Summary
My core work in deep learning makes use of a notion that I call 
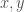

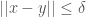



Though the runtime is already fast, often fractions of a second for a dataset with a few hundred rows, you can eliminate the training step embedded in this process, by simply estimating the value of 

Another layer of analysis you can apply that allows you to measure the confidence in a given probability makes use of my work in information theory, and in particular, the equation,
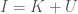
where 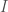


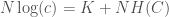
where 
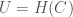
You can then require both the probability of a prediction, and your Knowledge in that probability, to exceed a given threshold in order to accept the prediction as valid.
Knowledge is in this case given by,
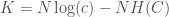
You can read about why these equations make sense in my paper, “Information, Knowledge, and Uncertainty“.
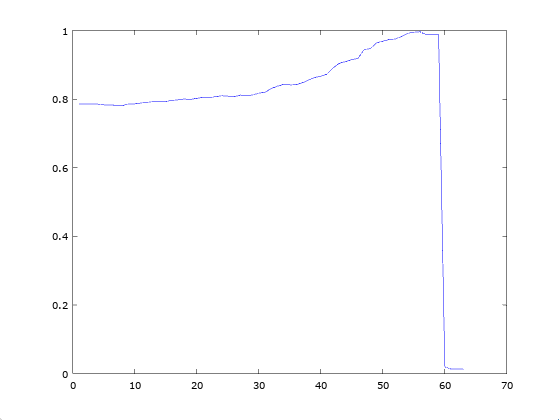
If you do this, it works quite well, and below is a plot of accuracy as a function of a threshold for both the probability and Knowledge, with Knowledge adjusted to an ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002)





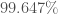
The results are comparable for the MRI Brain Cancer Dataset (max accuracy of 100%), Harvard Skin Cancer Dataset (max accuracy of 93.486%).