It just dawned on me that you can simply store positively and negatively charged particles separately (e.g., electrons and protons), just like cells do, to generate a difference in electrostatic charge, and therefore motion / electricity. I’m fairly confident space near Earth, is filled with charged particles, since my understanding is that the atmosphere is our primary defense against charged particles, and the source of the Aurora Borealis. So, by logical implication, you can collect and separate positively and negatively charged particles in space, bring them back down to Earth, and you have a battery. Moreover, because it’s subatomic particles, and not compounds, you have no chemical degradation, since you’re dealing with basically perfectly stable particles. As a consequence, you should be able to reverse the process indefinitely, assuming the battery is utilized by causing the electrons / protons to cross a wire and commingle. Said otherwise, there’s no reason why we can’t separate them again, producing yet another battery, repeating this indefinitely. I’m not an engineer, and so I don’t know the costs, but this is plainly clean energy, and given what a mess we’ve made of this place, I’m pretty sure any increased costs would be justified. Just an off the cuff idea, a negatively charged fluid could be poured into the commingled chambers, and drained, which should cause the protons to follow the fluid out, separating the electrons from the protons again.
Uncategorized
A Note on Net Versus Local Charge
I was puzzled by the motion of proteins within cells, which is apparently a still unsolved problem, and it dawned on me that whether or not this explains the motion, you could at least theorize that a given molecule prefers one medium over another medium, even if both have the same net charge, because of the distribution of the charges within each medium. That is, as a molecule gets larger, the small local electrostatic charges could produce macroscopic differences in behavior. So when a given molecule is equally distant from porous mediums A and B, each with the same net charge, it could be that the molecule naturally permeates one medium more often than another, due to the distribution of charges in the mediums and the molecule, not the net charges of either. This would allow for molecules and mediums with a net-zero charge to be governed by small scale electrostatic forces. If this in fact works, it would allow e.g., for DNA to produce protein mediums that are permeable only by molecules that have a particular distribution of charges, even if the net charge is zero. It would also allow for lock and key mechanisms at the molecular level (e.g., tubules), since the attraction could form a seal of sorts, which would not work unless the local charges map line up. This in turn would allow for specialization among tubules, where you could have multiple tubule types, each with their own corresponding charge distribution. It also implies that life could exist without organic chemistry, provided you have the same behaviors from some other set of compounds.
A Simple Multiverse Theory
In a footnote to one of my papers on physics (See Footnote 7 of A Unified Model of the Gravitational, Electrostatic, and Magnetic Forces), I introduced but didn’t fully unpack a simple theory that defines a space in which time itself exists, in that all things that actually happen are in effect stored in some space. The basic idea is that as the Universe changes, it’s literally moving in that space. That said, you could dispense with time altogether as in independent variable in my model, since time is the result of physical change, and so if there were no change at all to any system, you would have no way of measuring time, and therefore you could argue, that time is simply a secondary property imposed upon reality, that is measured through physical change.
However, we know that reality does in fact change, and we also have memories, which are quite literally representations of prior states of reality. This at least suggests the possibility that reality also has memory, that stores the prior, and possibly the future states of the Universe. Ultimately, this may be unnecessary, and therefore false, but it turns out you can actually test the model I’m going to present experimentally, and some known experiments are consistent with the model, in particular the existence of dark energy, and the spontaneous, temporary appearance of virtual particles at extremely small scales.
The basic idea is that you have a source, which generates what can be thought of as a Big Bang, producing an initial state of the Universe, 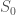
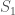

If we imagine the elements of each 



However, if we allow for small scale violations to this general idea of each snapshot of the Universe being independent, we could produce virtual particles that temporarily enter and then leave our timeline. This could also be the source of Dark Energy, that would constitute an unlikely, but possible macroscopic intrusion of energy from other timelines.
If the source at inception fires repeatedly, then you would have multiple instances of initial conditions that propagate in this space, but that’s perfectly fine, given the attractive and repulsive forces of gravity. If the source at inception generates the same initial conditions every time, then you’ll just have multiple instances of the same evolution. In this case, depending upon where we are positioned in the space of time itself, other snapshots of the Universe could literally contain our futures. If however, it generates different initial conditions, then you will have multiple evolutions. Ultimately, if the space of time truly exists, in this manner, then whether or not you have a multiverse, the past should be observable through some means, in particular, it should be possible to produce a virtual particle, that is a real particle in our timeline, and a virtual particle in another, and if it “comes back” with momentum that cannot be explained, then this would be evidence that it had in fact travelled to a different timeline, and interacted with an unknown system. Another test would be the existence of any wrong-way motion between energy that can’t be explained by other forces, suggesting the energy in question is not from our timeline, since in this view, mass that is not from our timeline is repelled.
Note that you don’t need a multiverse theory to explain either superposition or entanglement, at least in my model. Instead, superposition simply takes the fixed energy of a system, and allocates it to some number of possibilities, each being truly extant, with a fraction of the total energy of the system. Similarly, entanglement would occur in this view because you’ve simply taken the energy of some system, and split it macroscopically, creating two instances of the same system, each with less than the total energy, with the sum of the two equal to the total energy, that are therefore entangled, because they are one and the same system.
The Halting Problem And Provability
As a general matter, the question of whether or not a UTM will halt when given an input 



Now consider the question of whether you can prove that 
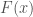
This leads to a set of questions:
1. If you can prove that a program 
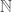

2. If you can prove that a program
3. If you can prove that a program
A program 


Note the existence of a single case where there is a proof, without a corresponding program
Computability and Optimization
I’ve developed an optimization algorithm that appears to be universal, in that it can solve superficially totally unrelated problems, e.g., sorting a list, balancing a set of weights, and high-dimensional interpolation. The algorithm itself doesn’t change in any material way, and what changes instead is the statement of what’s being optimized. In the case of a sorted list, I proved that a list is sorted if and only if adjacent terms have minimized distances, which allows sorting to be expressed in terms of optimization (i.e., minimize the distances between adjacent terms). This was not trivial to prove, and I’ve actually never heard of this result before, but more importantly, it suggests the general possibility that all computable problems can be expressed as optimization problems. If this is true, then my optimization algorithm would be able to solve any computable problem, with some non-zero probability. It’s not obvious whether this is true, nor is it obvious that it’s false, so I wouldn’t say it’s a conjecture, it is instead a question. As an example, how would you express Dijkstra’s Algorithm as an optimization problem? I thought about it just a bit, and quickly lost interest because I have too much going on, but the idea is there, and it’s interesting, because if it turns out that all computable problems are equivalent to some optimization problem, then my optimization algorithm has a non-zero probability of solving literally every computable problem. This would make the algorithm a universal problem solving algorithm, which would obviously be useful in A.I., though it already is plainly useful whether or not that’s true, since it can solve a wide class of problems.
Another interesting consequence stems from the observation that this algorithm, and many others, requires a random source (i.e., random number generation). However, a random source is not a feature in a pure UTM, and so it suggests the question of whether a UTM plus a random source is distinct from a UTM alone, and intuition suggests the answer is yes, but this is wrong. Specifically, it seems that a UTM plus a random source can solve problems a UTM alone cannot, which would be theoretically interesting, but is not true. Rather than use a random source, you can instead use a program that exhaustively and iteratively generates all possible values in a problem domain, and use this program to provide the otherwise random inputs to a Monte Carlo type algorithm, which proves equivalence, since every possibility generated by a random source will eventually be generated by the program, that by definition simply generates all possible values in order.
An Apparent Paradox In Probability
I believe it was Gödel who made the statement, “S = S is false”, famous, through his work on the foundations of mathematics, but I’m not completely certain of its history. In any case, it is an interesting statement to consider, because it plainly demonstrates the limitations of logic, which are known elsewhere, e.g., in the case of Turing’s Halting Problem, which similarly demonstrates the limits of computation. You can resolve S by simply barring self-reference, and requiring ultimate reference to some physical system. This would connect logic and reality, and since reality cannot realistically be inconsistent, you shouldn’t have any paradoxical statements in such a system. The Halting Problem however does not have a resolution, it is instead a fundamental limit on computing using UTMs. I discovered something similar that relates to the Uniform Distribution in work my on uncertainty, specifically, this is in Footnote 4 of my paper, Information, Knowledge, and Uncertainty:
“Imagine … you’re told there is no distribution [for some source], in that the distribution is unstable, and changes over time. Even in this case, you have no reason to assume that one [outcome is more] likely than any other. You simply have additional information, that over time, recording the frequency with which each [outcome occurs] will not produce any stable distribution. As a result, ex ante, your expectation is that each [outcome] is equally likely, [since you have no basis to differentiate between outcomes], producing a uniform distribution, despite knowing that the actual observed distribution cannot be a uniform distribution, since you are told beforehand that there is no stable distribution at all.”
From the perspective of pure logic, which is not addressed in the paper, this is an example where the only answer to a problem, is known to be wrong. We can resolve this apparent paradox by saying that there is no answer to the problem, since the only possible answer is also known to be wrong. Nonetheless, it is a bit unnerving, because logic leaves you with exactly one possibility, that is wrong, suggesting the possibility of other problems that have superficially correct answers, that are nonetheless wrong, because of non-obvious, and possibly logically independent considerations. This is not such a problem, because it is actually resolved by simply saying there is no distribution, which is perfectly consistent with the description of the problem, that assumes the distribution is not stable. The point being, that you could have superficially correct answers to some other problem, that are ultimately wrong due to information that you simply don’t have access to.
Probability, Complexity, and Indicia of Sentience
The market tanked about 4.0% this Tuesday, and I naturally searched for causes, like everyone else does, because the event is unlikely, in the sense that most trading days don’t produce such large moves in either direction. But I also acknowledge that it could have been a random outcome, in the most literal sense, that the motion of the S&P 500 was on that day determined by a repeated toll of a random variable, and that’s not something you can simply rule out. Nonetheless, the intuition is there, that low probability events are connected to causation, in the sense that they shouldn’t happen without an intervening cause, simply because they’re so unlikely. This view is however incomplete, and it’s something I’ve commented on in the past, specifically, that what you’re looking to is a property that has a low probability, rather than the event itself. In the case of an asset price, we’d be looking at paths that go basically straight up or straight down, which are few in number, compared to the rest of the paths that generally meander in no particular direction. This can be formalized using one of the first original datasets I put together, that generates random paths that resemble asset prices. In this dataset, there will be exactly two extremal paths that go maximally up and maximally down, and for that reason, those two paths are special, and from a simple counting perspective, there will be exactly two of them out of many.
To continue this intuition with another example, consider sequences generated by repeated coin tosses, e.g., HTH, being the product of flipping heads, then tails, then heads. The probability of any sequence is simply 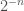

There is moreover, a plain connection between complexity and sentience, because anecdotally, that is generally how large and highly structured objects are produced, i.e., through deliberate action, though this is at times erroneous, since e.g., gravity produces simply gigantic, and highly structured systems, like our Solar System, and gravity is not in any scientific sense, sentient, and instead it has a simple mechanical behavior. However, there is nonetheless a useful, intuitive connection between the Kolmogorov Complexity and sentience, in that as you increase Kolmogorov Complexity from the mundane (e.g., (HHHHH …) or (HTHTHT …)) to the elaborate, but nonetheless patterned, it becomes intuitively more difficult to dismiss the possibility that the sequence was produced by a sentient being, as opposed to being randomly generated. Just imagine e.g., someone telling you that a randomly generated set of pixels produced a Picasso – you would refuse to believe it, justifiably, because highly structured macroscopic objects just don’t get generated that way.
And I’ve said many times, it is simply not credible in this view that life is the product of a random sequence, because that assumption produces probabilities so low, that there’s simply not enough time in the Universe to generate systems as complex as living systems. At the same time, an intervening sentient creator, only produces the same problem, because that sentience would in turn require another sentient creator, and so on. The article I linked to goes through some admittedly imprecise math, that is nonetheless impossible to argue against, but to get the intuition, there are 3 billion base pairs in human DNA. Each base pair is comprised of two selections from four possible bases, adenine (A), cytosine (C), guanine (G) [GWA-NeeN] or thymine (T). Ignoring restrictions, basic combinatorics says there are 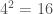


This is a joke of an idea, and instead, I think it is more likely that we just don’t understand physics, and that certain conditions can produce giant molecules like DNA, just like stars produce giant atoms. There is also a branch of mathematics known as Ramsey Theory, that is simply astonishing, and imposes structure on real-world systems, that simply must be there as a function of scale. There could be unknown results of Ramsey Theory, there could be unknown physics, probably both, but I don’t need to know what’s truly at work, since I don’t think it’s credible to say that e.g., DNA is “randomly generated”, as it’s so unlikely as popularly stated, that it’s unscientific.
Finally, in this view, we can make a distinct and additional connection between complexity and sentience, since we all know sentience is real, subjectively, and so it must have an objective cause, which could have something to do with complexity itself, since it seems to exist only in complex systems. Specifically, that once a system achieves a given level of complexity, it gives rise to sentience, as an objective phenomenon distinct from e.g., the body itself. This is not unscientific thinking at all, since it should be measurable, and we already know that certain living systems give rise to poorly understood fields, that are nonetheless measurable. Sentience would in this view be a field generated by a sufficiently complex system, that produces what we all know as a subjective experience of reality itself.
On Dissipating Charges
I noticed a long time ago that electrostatic attraction and repulsion seem fundamentally different from the dissipation of a charge in the form of a bolt, but I dropped the work (I have too much going on). Specifically, when you have a surplus of charges in one system, and a deficiency in the other, you get the normal acceleration of both systems (e.g., a balloon rubbed on someone’s hair will cause their hair to stand up towards the balloon).
Now consider for contrast, a bolt dissipating from a cloud. This is definitely due to the accumulation of a large amount of charge in the cloud. But if it were an explosion, you would have dissipating charges moving in all directions, which is exactly what you get from a kinetic explosion (e.g., a bomb blowing inside a container). Instead, what you see is a macroscopically contiguous system that we know is made of charges.
There are two obvious problems with this, the first is that explosions should cause dissipations that increase entropy, the second is that charges should be repelling each other, not following the same path. This suggests the possibility that a bolt is a fundamentally different state of a set of electrons, something along the lines of a macroscopic wave. This would solve both problems, since it would travel along a single path because it is a single system, and wouldn’t repel itself, because it’s one gigantic charge. Intuitively, it’s like a tau particle, in that it’s a massive single charge, that is obviously not stable.
There’s also the question as to why this would happen, and one simple explanation is that you have electrons leaving one configuration, and entering another. In contrast, the current in a wire is a set of electrons all traveling through what is effectively a single orbital that extends through the wire, the “valence orbital”, that isn’t really particular to any given atom. Where you have a break in the wire, you have what is basically a lightning bolt, again consistent with the idea that when an electron moves in one configuration of charges, it behave like a free electron, i.e. a single particle that changes position. When it changes configuration, you instead have a discrete change, e.g., jumping from a cloud to the ground, or from one valence to another, and it behaves like a bolt, which is just not the same as a free electron, since it is plainly comprised of more than one electron. If I had to guess, it travels at exactly c (i.e., the speed of light), when traveling as a bolt, whereas as a free electron, it does not, and again, I think this is because it is simply not the same state of matter as a free electron. Though a “lightning bolt” is comprised of many individual components, which would be bolts in this view, jumping from one configuration to the next, its velocity could be and is in fact slower than c, for the simple reason that it travels as a free electron in any given configuration, and only as a bolt (i.e., at c) between configurations.
Final Optimization Algorithm
I’ve finalized the N-Dimensional optimization algorithm I’ve been writing about lately, and this instance of it is set up to sort a list, though it can do anything. You need only remove the sections of code that prevent selection with replacement, and change the “eval” function (i.e., the function being optimized) to your liking. The reason it is set up to sort a list is to demonstrate the power of the algorithm, since there are approximately 
Another Updated N-Dimensional Optimization Algorithm
This is the final version, and as expressed, the optimization algorithm balances a set of weights on a beam, with corresponding symmetrical values intended to be equal. So far, it has found an exact solution every time I’ve run it. This same algorithm can also solve for interpolations, and any other goal-based problem. For interpolations, I’ve run it up to 12 variables, and the performance is excellent and fast.
