I was introduced to Williams Syndrome through my research on genetics, and it is rare among genetic diseases in the sense that it’s not all depressing, and in fact, people with Williams Syndrome are incredibly charming, emotive, and in some cases articulate people. The disease is the result of deletions on Chromosome 7, and Chromosome 7 is believed to be connected to language skills, and possibly socialization itself. Amazingly, people with Williams Syndrome are simply incredibly kind people, and some are brilliant musicians. As a general matter, people with Williams Syndrome have a great affinity for music, even if they are not themselves musicians, plainly suggesting a connection between musical aptitude and Chromosome 7. I didn’t look too far into the particulars, but I did come upon a video interview with a simply charming woman named Alexandra, who has Williams Syndrome. Williams Syndrome is at times associated with cognitive difficulties, but simply watching Alexandra, you can tell that she has basically none, and is instead, quite articulate, and moreover, she has a high level of self-awareness, and can describe her emotional state in detail, despite her disabilities. In particular, she said something that stuck with me, which is that she loves looking in the mirror, and I do as well, though not because I think I’m the most handsome man in the world, but because of an innate sense of not being alone as a consequence of simply looking in the mirror. And in fact, whenever I brainstorm, I always look in the mirror, as if I’m having a conversation.
Schizophrenics often have hallucinations that cause them to dislocate their consciousness, and assign it to a part of their body that makes no sense. So e.g., they might think their consciousness lives in a book across the room. This is obvious literally insane, and cannot possibly be physically true. However, I think it is the result of what are literally multiple functioning consciousnesses in one brain. This is not metaphysical, and instead, I think the brain of a person with Schizophrenia is literally subdivided, into two consciousnesses. This does not mean two brains, or two copies of the entire brain, but instead, multiple instances of the portion of the brain responsible for consciousness itself, not the rest of the brain. Because consciousness is physically real, there must be a cause for it, presumably in the brain, and as this mechanism develops, presumably during childhood, it could splinter into multiple instances, creating multiple consciousnesses in one brain.
This would allow for literal, self-awareness, in the sense that one region of the brain responsible for consciousness observes another region responsible for consciousness. This is in essence parallel computing, with communication between the UTMs, which can be accomplished simply through a single shared memory, which is obviously critical for any functioning human being. In fact, that could be one of the things that goes wrong with Schizophrenia, leading to proper multiple personalities, due to memory unique to one portion of the brain.
It would also allow for arbitrary scaling of consciousness, which in this view would scale the potential for literally parallel thoughts, and therefore faster more efficient thinking. This could explain how some people solve seemingly non-computable problems, through potentially arbitrarily large arrays of consciousness that are going to be difficult to describe in words, because by definition, you have multiple independent sequences of thoughts. If the mechanism of consciousness is in the brain, but driven and perhaps even housed in a field (e.g., the electrostatic fields in the brain generate a magnetic field literally separate from the body), then you could even have infinite independent consciousnesses in one brain. This sounds far out, but it’s not, because the shape of the field determines the number, and if the shape of the field is infinitely divisible, then you could have a shape with an infinite number of discrete components. Such a mind would be strictly superior to a UTM, which is obviously the case for some people.
Returning to Williams Syndrome, I think Alexandra experiences exactly that, i.e., another person in her mind when she looks in the mirror, albeit in a manner that is not destructive to her psyche, suggesting a connection between Williams Syndrome and Schizophrenia, and therefore Chromosome 7. This could explain why musicians (and Alexandra) really are unusually happy, energetic people:
They’re literally never alone.
And although it is only anecdotal, at the same time, it’s clear there’s a connection between creativity and madness, in that Quincy Jones’ mother was schizophrenic, and he is of course himself, plainly a brilliant musician, and Paul Erdös, Sir Isaac Newton, John Nash, John Nash’s son John Charles Nash (again implying heredity), Erik Satie, and Caravaggio all suffered at times from mental illness, possibly Schizophrenia. Caravaggio actually murdered a man, over a tennis game, indicating that he was plainly insane, despite the fact that he was a genius. This comes across from Alexandra, who cannot stand being alone, experiencing anxiety as a consequence. The net point being, there seems to be a connection between self-awareness, which comes across as emotional intelligence in the case of Alexandra, and Chromosome 7, and in turn, a connection between self-awareness and parallel computation, which could explain the nature of genius, and its lamentable connections to madness. Expressing this mechanically, the deletions on Chromosome 7 associated with Williams Syndrome, and musical and creative aptitude generally, and perhaps Schizophrenia, cause multiple instances of the mechanism responsible for consciousness in the brain to develop, causing the individual to literally think differently than normal people.
My list of crazy people is plainly anecdotal, but I thought it was worth noting that Erik Satie is the only musician on the list. This caused me to consider potential causes, under the assumption that musicians are less likely to be mentally ill than other geniuses. This is obviously counter to the popular perception of musicians as degenerates, but those people are popular musicians, and they are degenerates. In contrast, to knowledge, none of Mozart, Brahms, Bach, Liszt, Prokofiev, Chopin, Faure, Chausson, Debussy, and Ravel suffered from any mental illness at all, and in fact, they were all really well-adjusted, productive people. This led me to the primary difference between music and all other art forms, which is that music requires physical discipline over time, to play a note only at the exact right moment, in the exact right place, in the exact right manner. This plainly requires a regulatory function in the brain that prevents impulses from translating into errors. As a consequence, I think it makes perfect sense that musicians would be among the most well-adjusted geniuses, for the simple reason that they by definition have a high degree of physical discipline, which will prevent them from, e.g., stabbing a man over a tennis match. At the same time, because music is quantitative, I don’t think it’s any less challenging at the highest levels, than mathematics. And so, fine art musicians would be primary targets for genocide by people seeking to damage demographics, since they plainly posses high intellect, but are not degenerates.
 , of population size
, of population size  . Now imagine there’s exactly one member of the population that develops an inheritable, beneficial trait, through mutation. That person will have some number of offspring
. Now imagine there’s exactly one member of the population that develops an inheritable, beneficial trait, through mutation. That person will have some number of offspring  , and if the ratio
, and if the ratio  is not significant, that trait will not persist, because even if it’s dominant, it will be bred out to extinction in a few generations. This presents the fundamental insight for a hypothesis I just came up with, which is that microorganisms, particularly contagious microorganisms, could drive our evolution. Now imagine instead that a virus spreads through population
is not significant, that trait will not persist, because even if it’s dominant, it will be bred out to extinction in a few generations. This presents the fundamental insight for a hypothesis I just came up with, which is that microorganisms, particularly contagious microorganisms, could drive our evolution. Now imagine instead that a virus spreads through population 
 that begin with exactly the same structure, specifically, the same distribution of preferences, cash, and other assets among the individuals in the population. So for an individual
that begin with exactly the same structure, specifically, the same distribution of preferences, cash, and other assets among the individuals in the population. So for an individual 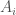 , there is some other individual
, there is some other individual  , with exactly the same preferences, cash supply, and other assets. As a consequence,
, with exactly the same preferences, cash supply, and other assets. As a consequence,  , where economies
, where economies 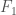 and
and 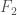 be equivalent functions run on the same UTM
be equivalent functions run on the same UTM  , in that
, in that  , for all
, for all  . During the operation of the functions, the tape of the UTM will change. Simply count the number of changes to the tape, which has units bits, which will allow us to compare the runtimes of the functions in the same units as the Kolmogorov Complexity. As a general matter, we can define a measure of runtime complexity,
. During the operation of the functions, the tape of the UTM will change. Simply count the number of changes to the tape, which has units bits, which will allow us to compare the runtimes of the functions in the same units as the Kolmogorov Complexity. As a general matter, we can define a measure of runtime complexity,  , given by the number of bits changed during the runtime of
, given by the number of bits changed during the runtime of  as applied to
as applied to 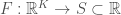 . Quantize
. Quantize  so that it creates
so that it creates  possible outcomes. Now assume that the predictions generated by
possible outcomes. Now assume that the predictions generated by 
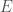 errors over
errors over 
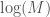 as a constant, and ignore it, we arrive at
as a constant, and ignore it, we arrive at 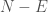 . This is simply the equation for accuracy, multiplied by the number of predictions. However, the number of predictions is relevant, since a small number of predictions doesn’t really tell you much. As a consequence, this is an arguably superior measure of accuracy, that is rooted in information theory. For the same reasons, it captures the intuitive connection between ordinary accuracy and uncertainty.
. This is simply the equation for accuracy, multiplied by the number of predictions. However, the number of predictions is relevant, since a small number of predictions doesn’t really tell you much. As a consequence, this is an arguably superior measure of accuracy, that is rooted in information theory. For the same reasons, it captures the intuitive connection between ordinary accuracy and uncertainty.