I’m working on formalizing an existing paper of mine on genetics that will cover the history of mankind using mtDNA and Machine Learning. Part of this process required me to reconsider the genome alignment I’ve been using, and this opened a huge can of worms yesterday, related to the very nature of reality and whether or not it is computable. This sounds like a tall order, but it’s real, and if you’re interested, you should keep reading. The work on the genetic alignment itself is basically done, and you can read about it here. The short story is, the genome alignment I’ve been using is almost certainly the unique and correct global alignment for mtDNA, for both theoretical and empirical reasons. But that’s not the interesting part.
Specifically, I started out by asking myself, what if I compare a genome to itself, except I shift one copy of the genome by a single base. A genome is a string of labels, e.g.,  . So if I were to shift
. So if I were to shift 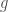 by one base in a modulo style (note that mtDNA is a loop), I would have
by one base in a modulo style (note that mtDNA is a loop), I would have  , shifting each base by one index, and wrapping T around to the front of the genome. Before shifting, a genome is obviously a perfect match to itself, and so the number of matching bases between and itself is 4. However, once I shift it by one base, the match count between and
, shifting each base by one index, and wrapping T around to the front of the genome. Before shifting, a genome is obviously a perfect match to itself, and so the number of matching bases between and itself is 4. However, once I shift it by one base, the match count between and  is 0. Now this is a fabricated example, but the intuition is already there: shifting a string by one index could conceivably completely scramble the comparison, potentially producing random results.
is 0. Now this is a fabricated example, but the intuition is already there: shifting a string by one index could conceivably completely scramble the comparison, potentially producing random results.
Kolmogorov Complexity
Andrey Kolmogorov defined a string  as random, which we now call Kolmogorov Random in his honor, if there is no compressed representation of that can be run on a UTM, generating as its output. The length of the shortest program
as random, which we now call Kolmogorov Random in his honor, if there is no compressed representation of that can be run on a UTM, generating as its output. The length of the shortest program  that generates on a UTM, i.e.,
that generates on a UTM, i.e.,  , is called the Kolmogorov Complexity of . As a result, if a string is Kolmogorov Random, then the Kolmogorov Complexity of that string should be approximately its length, i.e., the shortest program that produces is basically just a print function that takes as its input, and prints to the tape as output. As such, we typically say that the Kolmogorov Complexity of a Kolmogorov Random string is
, is called the Kolmogorov Complexity of . As a result, if a string is Kolmogorov Random, then the Kolmogorov Complexity of that string should be approximately its length, i.e., the shortest program that produces is basically just a print function that takes as its input, and prints to the tape as output. As such, we typically say that the Kolmogorov Complexity of a Kolmogorov Random string is  , where
, where  denotes the length of , and
denotes the length of , and  is a constant given by the length of the print function.
is a constant given by the length of the print function.
So now let’s assume I have a Kolmogorov Random string , and I again shift it by one base in a modulo style, producing  . Assume that is not Kolmogorov Random, and further, let
. Assume that is not Kolmogorov Random, and further, let  denote the length of and . Now consider the string
denote the length of and . Now consider the string  , i.e., entires
, i.e., entires  through of , and entries
through of , and entries  through
through 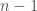 of . If
of . If  is not Kolmogorov Random, then it can be compressed into some string such that
is not Kolmogorov Random, then it can be compressed into some string such that  , where
, where  is some UTM and the length of is significantly less than the length of . But this implies that we can produce , by first generating , and then appending
is some UTM and the length of is significantly less than the length of . But this implies that we can produce , by first generating , and then appending  to the end of . But this implies that can be generated by another string that is significantly shorter than itself, contradicting the assumption that is Kolmogorov Random. Therefore, must be Kolmogorov Random. Note that we can produce by removing the first entry of . Therefore, if is not Kolmogorov Random, then we can produce by first generating using a string significantly shorter than
to the end of . But this implies that can be generated by another string that is significantly shorter than itself, contradicting the assumption that is Kolmogorov Random. Therefore, must be Kolmogorov Random. Note that we can produce by removing the first entry of . Therefore, if is not Kolmogorov Random, then we can produce by first generating using a string significantly shorter than  , which contradicts the fact that must be Kolmogorov Random. Therefore, is Kolmogorov Random.
, which contradicts the fact that must be Kolmogorov Random. Therefore, is Kolmogorov Random.
This is actually a really serious result, that might allow us to test for randomness, by shifting a given string by one index, and testing whether comparing matching indexes produce statistically random results. Note that unfortunately, the Kolmogorov Complexity is itself non-computable, so we cannot test for randomness using the Kolmogorov Complexity itself, but as you can see, it is nonetheless a practical, and powerful notion.
Computation, Uncertainty, and Uniform Distributions
Now imagine we instead begin with the string  . Clearly, if we shift by 1 index, the match count will drop to exactly 0, and if we shift again, it will jump back to 8, i.e., the full length of the string. This is much easier to do in your head, because the string has a clear pattern of alternating entries, and so a bit of thinking shows that shifting by 1 base will cause the match count to drop to 0. This suggests a more general concept, which is that uncertainty can arise from the need for computational work. That is, the answer to a question could be attainable, provided we perform some number of computations, and prior to that, the answer is otherwise unknown to us. In this case, the question is, what’s the match count after shifting by one base. Because the problem is simple, you can do this in your head.
. Clearly, if we shift by 1 index, the match count will drop to exactly 0, and if we shift again, it will jump back to 8, i.e., the full length of the string. This is much easier to do in your head, because the string has a clear pattern of alternating entries, and so a bit of thinking shows that shifting by 1 base will cause the match count to drop to 0. This suggests a more general concept, which is that uncertainty can arise from the need for computational work. That is, the answer to a question could be attainable, provided we perform some number of computations, and prior to that, the answer is otherwise unknown to us. In this case, the question is, what’s the match count after shifting by one base. Because the problem is simple, you can do this in your head.
But if I instead asked you the same question with respect to  , you’d probably have to grab a pen and paper, and carefully work out the answer. As such, your uncertainty with respect to the same question depends upon the subject of that question, specifically in this case, and . The former is so simple, the answer is obvious regardless of how long the string is, whereas the latter is idiosyncratic, and therefore, requires more computational work. Intuitively, you can feel that your uncertainty is higher in the latter case, and it seems reasonable to connect that to the amount of computational work required to answer the question.
, you’d probably have to grab a pen and paper, and carefully work out the answer. As such, your uncertainty with respect to the same question depends upon the subject of that question, specifically in this case, and . The former is so simple, the answer is obvious regardless of how long the string is, whereas the latter is idiosyncratic, and therefore, requires more computational work. Intuitively, you can feel that your uncertainty is higher in the latter case, and it seems reasonable to connect that to the amount of computational work required to answer the question.
This leads to the case where you simply don’t have an algorithm, even if such an algorithm exists. That is, you simply don’t know how to solve the problem in question. If in this case, there is still some finite set of possible answers, then you effectively have a random variable. That is, the answer will be drawn from some finite set, and you have no means of calculating the answer, and therefore, no reason to distinguish between the various possible answers, producing a uniform distribution over the set of possible answers. This shows us that even a solvable, deterministic problem, can appear random due to subjective ignorance of the solution to the problem.
Deterministic Randomness
I recall a formal result that gives the density of Kolmogorov Random strings for a given length , but I can’t seem to find it. However, you can easily show that there must be at least one Kolmogorov Random string of every length . Specifically, the number of strings of length less than or equal to is given by  . The number of strings of length
. The number of strings of length  is instead
is instead 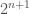 , and as such, there is at least 1 Kolmogorov Random string of length , since there aren’t enough shorter codes. As a result, we can produce Kolmogorov Random strings by simply counting, and producing all strings of length
, and as such, there is at least 1 Kolmogorov Random string of length , since there aren’t enough shorter codes. As a result, we can produce Kolmogorov Random strings by simply counting, and producing all strings of length  , though we cannot test them individually for randomness since the Kolmogorov Complexity is non-computable.
, though we cannot test them individually for randomness since the Kolmogorov Complexity is non-computable.
In fact, I proved a corollary that’s even stronger. Specifically, you can prove that a UTM cannot cherry pick the random strings that are generated by such a process. This is however a corollary of a related result, which we will prove first, that a UTM cannot increase the Kolmogorov Complexity of an input.
Let 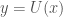 . Since generates
. Since generates  when is given as the input to a UTM, this in turn implies that
when is given as the input to a UTM, this in turn implies that  . That is, we can generate by first running the shortest program that will generate , which has a length of
. That is, we can generate by first running the shortest program that will generate , which has a length of  , and then feed back into the UTM, which will in turn generate . This is simply a UTM that runs twice, the code for which will have a length of that does not depend upon , which proves the result. That is, there is a UTM that always runs twice, and the code for that machine is independent of the particular under consideration, and therefore its length is given by a constant . As such, the complexity of the output of a UTM is strictly less than or equal to the complexity of its input.
, and then feed back into the UTM, which will in turn generate . This is simply a UTM that runs twice, the code for which will have a length of that does not depend upon , which proves the result. That is, there is a UTM that always runs twice, and the code for that machine is independent of the particular under consideration, and therefore its length is given by a constant . As such, the complexity of the output of a UTM is strictly less than or equal to the complexity of its input.
This is a counterintuitive result, because we think of machines as doing computational work, and that connotes new information is being produced, but in the strictest sense, this is just not true. Now, as noted above, computational work is often required to answer questions, and so in that regard, computational work can alleviate uncertainty, but it cannot increase complexity in the sense of the Kolmogorov Complexity. Now we’re ready for the second result, which is that a UTM cannot cherry pick Kolmogorov Random strings.
Assume that we have some program that generates strings, at least some of which are Kolmogorov Random, and that  never stops producing output. Because never terminates, and there are only so many strings of a given length, the strings generated by must eventually increase in length, and that cannot be a bounded process. As such, if never stops generating Kolmogorov Random strings, then those Kolmogorov Random strings must eventually increase in length, and that again cannot be a bounded process, producing arbitrarily long Kolmogorov Random strings. This implies that will eventually generate a Kolmogorov Random string , such that
never stops producing output. Because never terminates, and there are only so many strings of a given length, the strings generated by must eventually increase in length, and that cannot be a bounded process. As such, if never stops generating Kolmogorov Random strings, then those Kolmogorov Random strings must eventually increase in length, and that again cannot be a bounded process, producing arbitrarily long Kolmogorov Random strings. This implies that will eventually generate a Kolmogorov Random string , such that  . However, this implies that
. However, this implies that  . Note that the result above proves that a UTM cannot add complexity to its input. Therefore, if eventually generates then there cannot be some other program that can isolate as output from the rest of the output generated by , otherwise the result above would be contradicted.
. Note that the result above proves that a UTM cannot add complexity to its input. Therefore, if eventually generates then there cannot be some other program that can isolate as output from the rest of the output generated by , otherwise the result above would be contradicted.
This second result shows that there are serious limitations on the ability of a UTM to deterministically separate random and non-random strings. Specifically, though it’s clear that a UTM can generate random strings, they cannot be isolated from the rest of the output, if the random strings are unbounded in length.
Computable Physics
Now we’re ready for a serious talk on physics. When people say, “that’s random”, or “this is a random variable”, the connotation is that something other than a mechanical process (i.e., a UTM) created the experience or artifact in question. This is almost definitional once we have the Kolmogorov Complexity, because in order for a string to be random, it must be Kolmogorov Random, which means that it was not produced by a UTM in any meaningful way, and was instead simply printed to the output tape, with no real computational work. So where did the random string come from in the first instance?
We can posit the existence of random sources in nature, as distinct from computable sources, but why would you do this? The more honest epistemological posture is that physics is computable, which allows for Kolmogorov Random artifacts, and non-random artifacts, since again, UTMs can produce Kolmogorov Random strings. There are however, as shown above, restrictions on the ability of a UTM to isolate Kolmogorov Random strings from non-random strings. So what? This is consistent with a reality comprised of a mix of random and non-random artifacts, which sounds about right.
Now what’s interesting, is that because integers and other discrete structures are obviously physically real, we still have non-computable properties of reality, since e.g., the integers must have non-computable properties (i.e., the set of properties over the integers is uncountable). Putting it all together, we have a computable model of physics, that is capable of producing both random and non-random artifacts, with at least some limitations, and a more abstract framework of mathematics itself that also governs reality in a non-mechanical manner, that nonetheless has non-computable properties.
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
