I noted in my paper, A New Model of Computational Genomics [1], that imputation using sequential bases is categorically inferior to using random bases, in several experiments testing the extent of imputation. That is, if you select 
Specifically, the attached code generates a set of bases in common for every population in a dataset of human mtDNA genomes. For example, the algorithm finds all bases that are common to Chinese individuals, and stores that as what is in essence a reference genome for the Chinese population. If a gene is common to all Chinese individuals, then it must be included in this reference genome, since the reference genome contains all bases common to the Chinese, and therefore, all genes common to the Chinese, in addition to any other bases they share as a population. All of the genomes are complete genomes taken from the NIH Database, and include provenance files with links to the NIH Database.
The next step is to predict the ethnicity of an individual using those reference genomes. Specifically, the algorithm takes a given testing genome, and finds the reference genome to which it is most similar. This process has an accuracy of approximately 

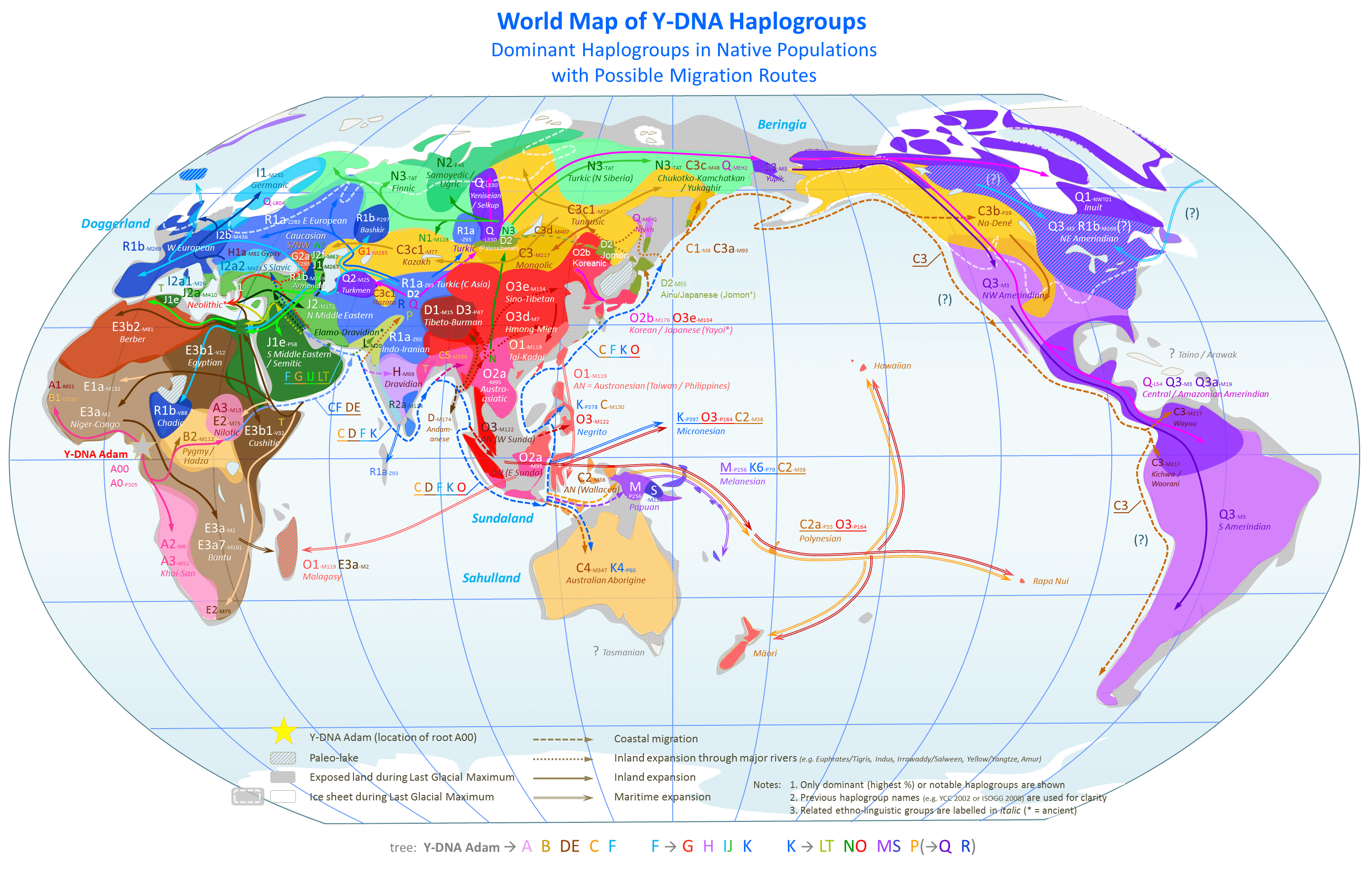
Haplogroups are plainly not precise, which you can see in the map above, that shows haplogroups crossing national boundaries. Moreover, discovering haplogroups requires a lot of work. In contrast, the software in [1] is capable of predicting ethnicity at the national level, with no human analysis ex ante, with an accuracy of about 80%. For example, the algorithms in [1] can discern between Swedes and Norwegians, whereas the haplogroups shown above plainly cannot, and instead Swedes and Norwegians are grouped together, though both are distinguished from Finns. Moreover, the attached code casts serious doubt on using genes and haplogroups for analyzing ancestry, since they’re apparently incapable of predicting ethnicity, which should be easier. That is, ancestry posits something in addition to ethnicity, which is that one ethnicity is the ancestor of another, and therefore, ancestry should be more difficult to predict than ethnicity alone.
My opinion is that these results suggest circular reasoning in the construction of haplogroups, where national, geographic, and language groups are used to define populations, and then common genes are identified, rather than allowing the genomes themselves to define groups of people, without reference to anything exogenous to the genomes. Moreover, this software shows that common genes do not allow you to predict ethnicity. In contrast, the software in [1] learns from a dataset of stated ethnicities, and is then able to predict the ethnicity of other genomes, without any human analysis at all. And again, the software in [1] is plainly more precise than haplogroups, in any case. Therefore, taken as a whole, [1] appears to present a superior method of analyzing ethnicity and ancestry, which is to use whole-genomes, treat the stated national / linguistic ethnicities as bona fide, and allow software to identify any relevant features. Moreover, the software in [1] also allows for the construction of populations that are based solely upon the genomes themselves, thereby allowing for the mechanistic, and therefore objective, construction of genetic groups, independent of national, geographic, and language groups.
Here’s the code and the dataset, and any missing code is linked to in [1]:
https://www.dropbox.com/s/6x8796m9hi9h934/Uniform_Bases_Prediction_CMDNLINE.m?dl=0
https://www.dropbox.com/s/zwt1bcqqmqkleca/mtDNA.zip?dl=0
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
