It must be the case that mtDNA carries information about paternal lineage, since you can predict ethnicity using mtDNA alone, with an accuracy of about 80%. See, A New Model of Computational Genomics [1], generally. Chance, at least with respect to the dataset in [1], implies an accuracy of about 3%, since there are 36 ethnicities in that dataset. There’s a question of how this could be, since mtDNA is inherited directly from the mother, with very little, possibly no variation from one generation to the next. I posited that the mechanics of DNA replication are at least partially inhereted from the paternal, which would cause similar rates of mutations in mtDNA in people that have the same paternal line, despite the fact that mtDNA is inhereted directly from the mother. For example, just assume arguendo, the ribosome is inherited from the paternal line. It follows that the probability of an error during replication is determined by the paternal line. Specifically, it should be the case that the probability of an error during replication is roughly constant over the entire genome. As a consequence, if a single paternal line exists in a population, the entropy of the distribution of bases along the entire genome should be roughly. Moreover, a less sophisticated argument is that it’s simply male selection that alters the distribution of otherwise highly similar maternal lines. That is, you two take identical instances of the same maternal line, introduce them to two different paternal lines, selection alone could produce variation, which should show up in the charts below.
This is in fact the case for at least some homogenous populations, in particular, the Iberian Roma and Papuans. These two populations are a 99% match on the maternal line (See [1] generally), despite the fact they look completely different, and one lives in Spain, and the other lives in Papua. This suggests that they should have different paternal lines. If my hypothesis is correct, then the entropy of the distribution of bases along the genome should be different, and they are. See below, with the Papuan entropy plotted on the left, and the Iberian Roma entropy plotted on the right. The calculation is straightforward: each index along the genome will constitute a distribution of bases over the population, which will therefore have an entropy. The entropy at each index along the genome is plotted below. If the paternal line is uniform, then the probability of mutation should be uniform at each index, creating a uniform value of entropy along the genome. If the probability of error is low, then the entropy should be low. As you can see, the Roma (on the right), are not only more homogenous in the distribution of entropy, they also have a lower entropy overall. This suggests a lower rate of mutation over time, and a homogenous distribution of paternal lines, since if there were many paternal lines, the variance of the entropy should be high, and it is instead low. That is, if you have many paternal lines, then you don’t have a single distribution of mutation at each index, since you have many overlapping distributions, which should cause variance in the entropy over the entire genome. Therefore, the average entropy over the genome is indicative of the rate of mutation in the population, and the standard deviation of the entropy over the genome is indicative of the number of paternal lines. Note that because both the Roma and Papuans are basically identical on the maternal line, the fact that the distribution of entropy is so drastically different between the populations, is itself evidence for the claim that the paternal line impacts the replication of mtDNA.
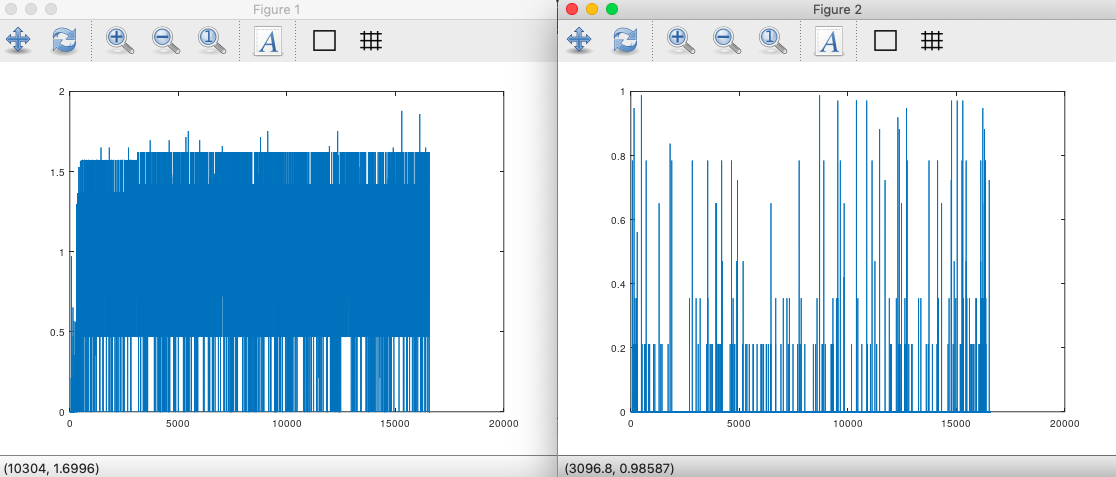
This is in contrast to a more heterogenous population, like the Norwegians. In this case, not only is the implied rate of mutation higher, the variance of the entropy is also higher. This in turn implies that the Norwegians have a more heterogenous set of paternal lines than the Roma and Papuans, which makes perfect sense, since they also have a more heterogenous set of maternal lines. Here’s the same plot for the Norwegians, and as you can see, I’m right, as usual.
Here’s the code, any missing code and the dataset itself can be found in links in [1]:
https://www.dropbox.com/s/jcar7gged7io5oi/Genome_Entropy_CMNDLINE.m?dl=0
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
