It just dawned on me that my paper, Information, Knowledge, and Uncertainty [1], seems to allow us to measure the amount of information a predictive function provides about a variable. Specifically, assume 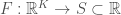 . Quantize
. Quantize  so that it creates
so that it creates  uniform intervals. It follows any sequence of
uniform intervals. It follows any sequence of  predictions can produce any one of
predictions can produce any one of  possible outcomes. Now assume that the predictions generated by
possible outcomes. Now assume that the predictions generated by  produce exactly one error out of predictions. Because this system is perfect but for one prediction, there is only one unknown prediction, and it can be in any one of states (i.e., all other predictions are fixed as correct). Therefore,
produce exactly one error out of predictions. Because this system is perfect but for one prediction, there is only one unknown prediction, and it can be in any one of states (i.e., all other predictions are fixed as correct). Therefore,

As a general matter, our Knowledge, given 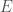 errors over predictions, is given by,
errors over predictions, is given by,

If we treat 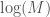 as a constant, and ignore it, we arrive at
as a constant, and ignore it, we arrive at 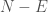 . This is simply the equation for accuracy, multiplied by the number of predictions. However, the number of predictions is relevant, since a small number of predictions doesn’t really tell you much. As a consequence, this is an arguably superior measure of accuracy, that is rooted in information theory. For the same reasons, it captures the intuitive connection between ordinary accuracy and uncertainty.
. This is simply the equation for accuracy, multiplied by the number of predictions. However, the number of predictions is relevant, since a small number of predictions doesn’t really tell you much. As a consequence, this is an arguably superior measure of accuracy, that is rooted in information theory. For the same reasons, it captures the intuitive connection between ordinary accuracy and uncertainty.
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
