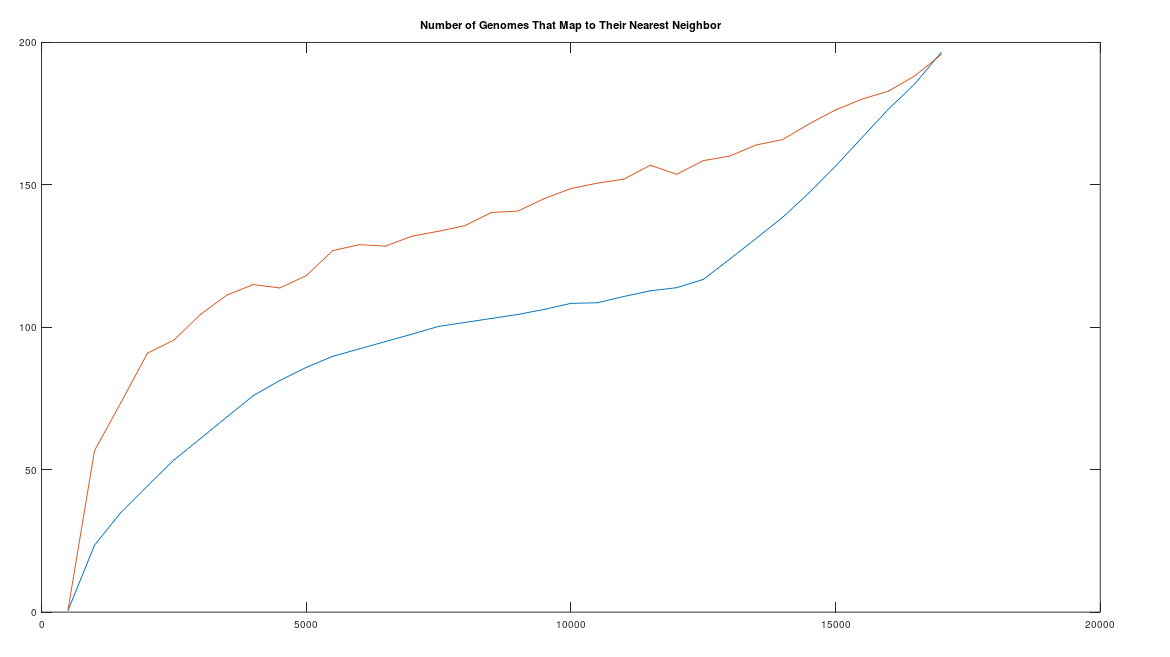
The methods I’ve been using to analyze mtDNA so far, have absolutely nothing to do with Haplogroups or even genes, and instead, I’m simply reading the entire genome, and treating every base as equally likely to provide information about nationality and heredity generally. So far, it’s worked really well, in that it produces incredibly efficient and accurate algorithms. However, I just developed a formal test of this method, and it turns out that the test is consistent with the notion that my method is actually better than looking at Haplogroups and genes. Specifically, I repeatedly ran Nearest Neighbor in two contexts, one where I incrementally increased the length of a contiguous sequence of bases (i.e., bases 1 through , increasing ), and counted how many genomes mapped to their true nearest neighbor. Then, I increased the size of a random set of indexes, and ran nearest neighbor using only those indexes (i.e., increasing the size of a random set of indexes from to , where is the size of the genome). The chart below shows the number of genomes that map to their true nearest neighbor (y-axis), as a function of the number of bases in scope (x-axis). In order to be certain that neither was the result of an idiosyncratic outcome, the curves shown below are both the product of an average over 10 independent iterations. Specifically, for the sequential bases, I shifted the initial index each iteration, going from index to , thereby testing multiple independent starting indexes. If the sequence pushed past the end (i.e., ), I simply started again from other side using modular indexes (i.e., modulo , causing e.g., to map to ). For the random bases, I simply generated 10 independent iterations of the algorithm, and took the average, since it produces random indexes anyway. There are again two applications of this method, and therefore two plots, one with sequential bases, and the other with random bases. The length of both curves is 34 entries long, and the random curve was superior (i.e., more rows mapped to their true nearest neighbor) for 33 of those 34 entries, again, using an average taken over 10 independent iterations.
The number of genomes that map to their true nearest neighbors (y-axis) as a function of the number of bases considered (x-axis). The random curve is on top in orange, the sequential curve below that in blue.
This is consistent with the hypothesis that by fixing the first sequential bases in a genome, you actually learn less about the genome than you do by fixing random bases. This suggests that for at least some purposes, disregarding potential genes and Haplogroups could be more useful, and is almost certainly more efficient. Interestingly, it is also consistent with an abstract notion of symmetry, where fixing a part of a system, implies some aspect of its whole, just like an axis of symmetry causes one set of points to imply another. In this case, a portion of the genome eventually implies a property of the whole, which is the nearest neighbor of the genome. This suggests a deep question, which is, what can be known about a random sequence? Yes, I’m assuming DNA genomes are Kolmogorov random, or close to it, and the point is, generally, what kind of predictions can be made given compressed instances of random systems? It seems like you can still predict the nearest neighbor of an mtDNA genome, given only part of it. This doesn’t run afoul of the notion of Kolmogorov randomness, since it doesn’t imply that you can compress the genome itself and still produce the genome. It does however, suggest the possibility that meaningful predictions can still be made given partial information about a random system.
Attached is code that allows you to run this analysis and generate the chart above, together with the dataset, which now contains 198 complete human mtDNA genomes.