Attached is some code that makes use of a measure of correlation I mentioned in my first real paper on A.I. (see the definition of “symm”) that I’ve finally gotten around to coding as a standalone measure.
The code is annotated to explain how it works, but the basic idea is that sorting reveals information about the correlation between two vectors of numbers. For example, imagine you have a set of numbers from 1 to 100, listed in ascending order, in vector 

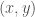
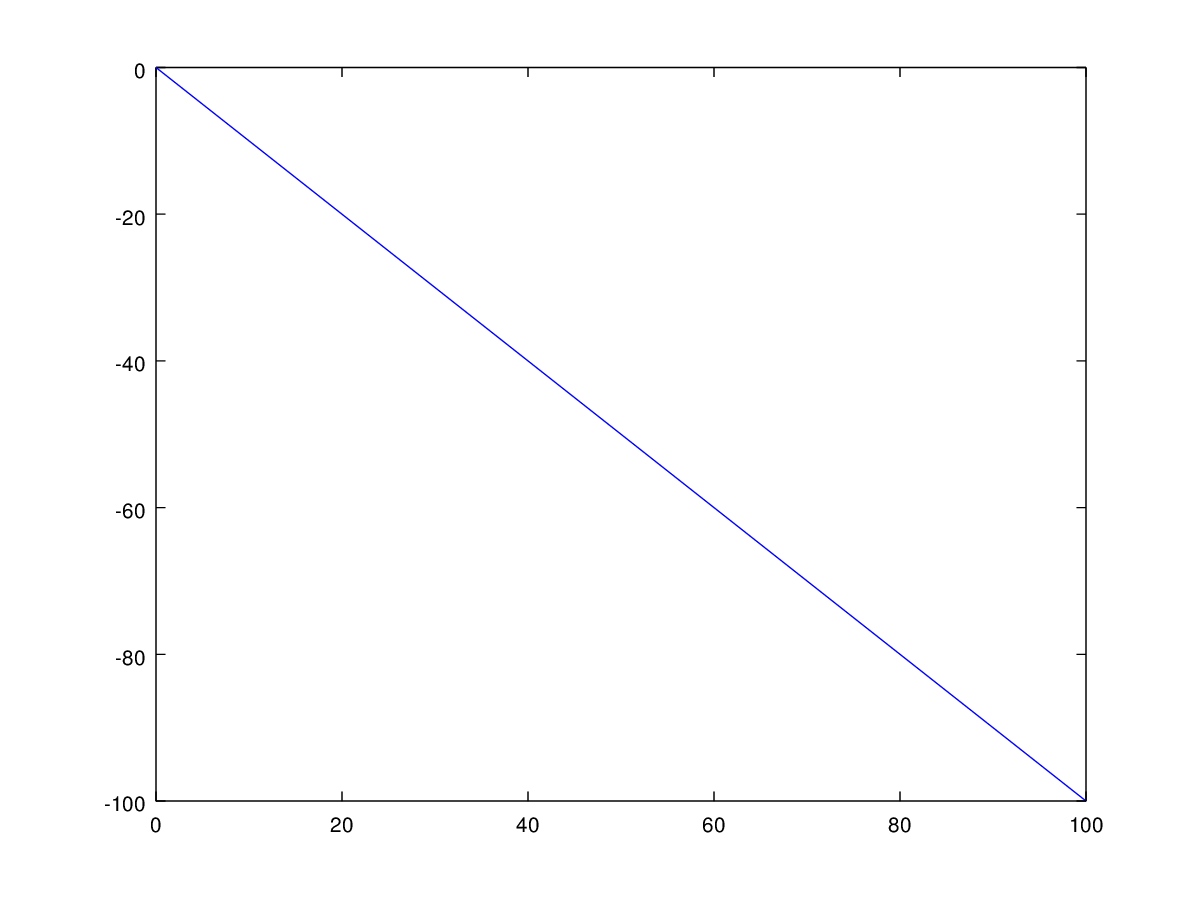
Now sort each set of numbers in ascending order, and save the resultant mappings of ordinals. For example, in the case of vector 


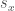
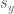
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Because I’ve abstracted sorting using information theory, you could I suppose measure the correlation between any two ordered sets of mathematical objects.
Also attached is another script that uses basically the same method to measure correlation between numerical data and ordinal data. The specific example attached allows you to measure which dimensions in a dataset (numerical) are most relevant to driving the value of the classifier (ordinal).
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
