My core work in deep learning makes use of a notion that I call , which is the minimum distance over which distinction between two vectors is justified by the context of the dataset. As a consequence, if you know , then by retrieving all vectors in the dataset for which , you can thereby generate a cluster associated with the vector . This has remarkable accuracy, and the runtime is , where is the number of rows in the dataset, on a parallel machine. You can read a summary of the approach and the results as applied to benchmark UCI and MNIST datasets in my article, “Vectorized Deep Learning“.
Though the runtime is already fast, often fractions of a second for a dataset with a few hundred rows, you can eliminate the training step embedded in this process, by simply estimating the value of using a function of the standard deviation. Because you’re estimating the value of , the cluster returned could very well contain vectors from other classes, but this is fine, because you can then use the distribution of classes in the cluster to assign a probability to resultant predictions. For example, if you query a cluster for a vector , and get a cluster , and the mode class (i.e., the most frequent), has a density of within , then you can reasonably say that the probability your answer is correct is . This turns out to not work all the time, and very well sometimes, depending upon the dataset. It must work where the distribution of classes about a point is the same in the training and testing datasets, and this follows trivially from the lemmas and corollaries I present in my article, “Analyzing Dataset Consistency“. But of course, in the real world, these assumptions might not hold perfectly, which causes performance to suffer.
Another layer of analysis you can apply that allows you to measure the confidence in a given probability makes use of my work in information theory, and in particular, the equation,
,
where is the total information that can be known about a system, is your Knowledge with the respect to the system, and is your Uncertainty with respect to the system. In this case, the equation reduces to the following:
,
where is the size of the prediction cluster, is the number of classes in the dataset, is again Knowledge, and is the Shannon Entropy of the prediction cluster, as a function of the distribution of classes in the cluster.
You can then require both the probability of a prediction, and your Knowledge in that probability, to exceed a given threshold in order to accept the prediction as valid.
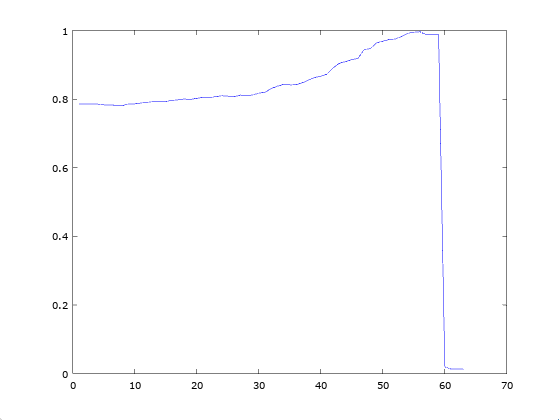
If you do this, it works quite well, and below is a plot of accuracy as a function of a threshold for both the probability and Knowledge, with Knowledge adjusted to an scale, given rows of the MNIST Fashion Dataset. The effect of this is to require an increasingly high probability, and increasing confidence in your measure of that probability. The dataset is then broken into random training and random testing rows, done times. The accuracy shown below is the average over each of the runs, as a function of the minimum threshold, which is again, applied to both the accuracy and the confidence. The reason the prediction drops to at a certain point, is because there are no rows left that satisfy the threshold. The accuracy peaks at , and again, this is without any training step, so it is in fairness, an unsupervised algorithm.

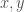

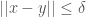





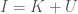
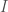


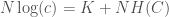

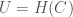
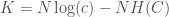
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002)






Pingback: Updated Sort-Based Classification | Information Overload