This method is already baked into some of my most recent posts, but I wanted to call attention to it in isolation, because it is interesting and useful. Specifically, my algorithms are generally rooted in a handful of lemmas and corollaries that I introduced, that prove, that the nearest neighbor method produces perfect accuracy, when classifications don’t change over small fixed distances. That is, if I’m given a row vector 

It uses a fixed form formula to calculate
This results in a prediction algorithm that has 
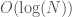
Here are the results as applied to the MNIST Fashion Dataset using 7,500 randomly selected rows, run 500 times, on 500 randomly selected training / testing datasets:
1. Nearest Neighbor:
Accuracy: 87.805% (on average)
2. Cluster-Based:
Accuracy: 93.188% (on average)
Given 500 randomly selected training / testing datasets, the cluster-based method beat the accuracy of nearest neighbor method 464 times, the nearest neighbor method beat the cluster-based method 0 times, and they were equal 36 times. The runtime from start to finish is a few seconds (for a single round of predictions), including preprocessing the images, running on an iMac.
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
