NOTE: there is an error in the code, that I am deliberately leaving, because I can’t explain why accuracy actually increases as the code is written, as a function of confidence. I’m working on something else at the moment, post coming soon, but I wanted to flag the error, and the related apparent mystery. In short, the code as written returns the cluster for a random row of the dataset, rather than the row that the input vector mapped to.
Attached is code that implements information-based measures of confidence, that allows you to filter predictions based upon confidence, in turn improving accuracy. Below are two images, one showing the total number of errors for each class of the dataset as a function of confidence (on the left), and another showing overall accuracy as a function of confidence (on the right), each as applied to the Harvard Skin Cancer Dataset, which I’ve found to be awful, as the images are not consistent, and one class makes up basically all of the data.
In each case, prediction was run 1,000 times, using 1,000 randomly generated training and testing datasets, comprised of 350 rows, which is a very small subset of the roughly 10,000 rows of the dataset. This is why the number of errors begins in the thousands, because it is the total over all runs (bottom image). In contrast, the accuracy is the average accuracy at a given level of confidence (x-axis) over all runs (top image). The purpose of this initial note is to demonstrate that the measure of confidence works, and later, I will run the same simulation on the full dataset, to demonstrate that not only does the measure of confidence work, but it also works in solving practical datasets, increasing accuracy. In any case, because it was a such a challenging dataset, it lead to this implementation, which was ultimately a good thing.

The fundamental principle underlying the measure of confidence, is the equation I introduced a while back, which is 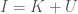



Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
