I’ve just applied my basic supervised image classification algorithm (see Section 1.2 of this paper) to an MRI image classification dataset from Kaggle, and a Skin Cancer classification dataset from Harvard. The MRI Dataset classification task is to classify the type of brain tumor, or absence thereof, given four classes. The accuracy for the MRI Dataset is consistently around 100% (using randomized partitions into training / testing datasets), and the runtime over 1503 training rows is 15 seconds (including pre-processing) running on an iMac.
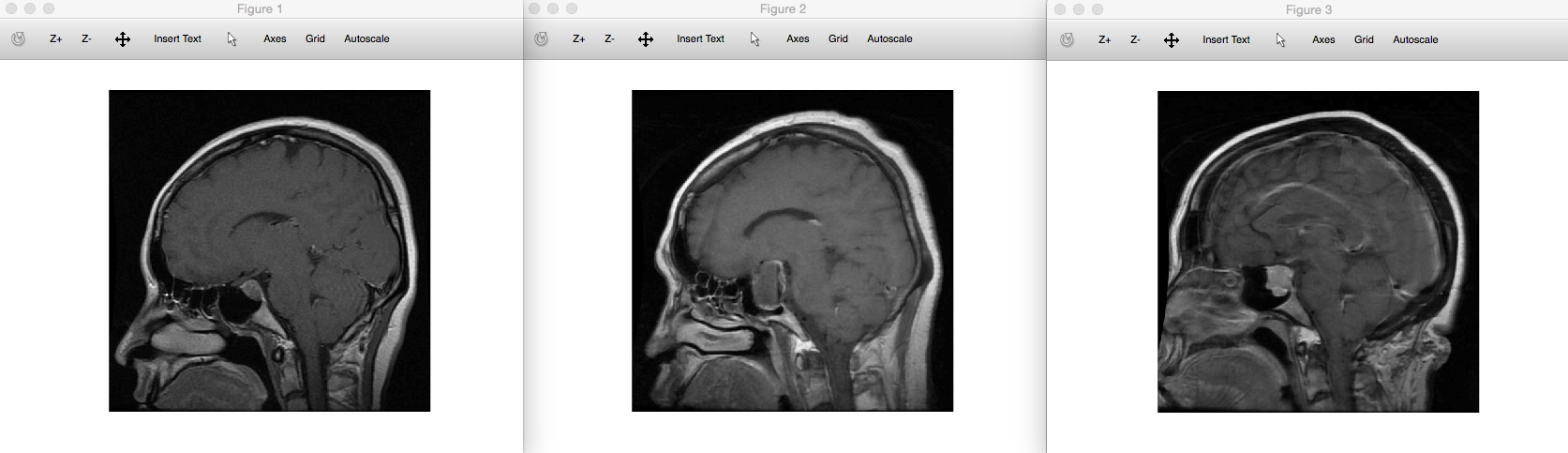
I’ve also applied the supervised clustering algorithm (see the same paper above) to the MRI dataset, which has an accuracy around 94%. This would allow doctors to not only diagnose patients with great accuracy on a cheap computer, since the clustering step would also allow them to compare the most similar brain scans. Clustering the entire testing dataset of 376 rows in this case took about 10 seconds, running on an iMac. For example, the left most image above is an input image of a pituitary brain tumor, and the two images to the right of that are the images returned by the clustering algorithm, both of which also represent brains with pituitary tumors.
The downside to my approach is that the algorithm “rejects” a large number of rows from the testing dataset as outside of the scope of the training dataset (always on a blind basis, based upon only training data). Without getting too into details, you can soften the standard it uses to reject data, and if you do so, of course, the percentage of rows that gets rejected starts to decrease, though accuracy starts to suffer.
So what I’ve done for the Skin Cancer dataset is to allow a sliding scale of precision, that rejects fewer and fewer rows, and reports the classification prediction accuracy at each scale. This lets the user decide whether they want basically perfect confidence in their predictions, at the expense of rejecting a large portion of the testing dataset, or somewhere just beyond that, perhaps significantly so, if they’re more interested in bulk predictions than precision. For the Skin Cancer Dataset, this produces accuracies that range from 100%, with a rejection rate of 99.750%, to 85.750%, with a rejection rate of 0%, which is effectively unsupervised nearest neighbor. Note that I’ve consolidated all of the malignant classes into one class, leaving the benign class as the second class. I’ve also converted the dataset to grey scale, so it’s possible you’d get even better accuracy using full color, since from what I understand, color is relevant to classifying skin lesions. You could tweak these techniques, to, for example, reduce the rejection rate until it hits zero, whereas I’ve used a fixed number of iterations for simplicity, for now.
Finally, note that the Skin Cancer dataset contains not proper duplicates, but at times multiple photos of the same patient’s lesions, so as a temporary fix, I’ve randomly selected a subset of the total dataset, which means the issue shouldn’t occur too often, since the number of rows selected is 2000, out of roughly 10,000, and the number of duplicates is typically 2 or 3. I’ve already fixed this formally, by selecting exactly one image for each patient, and the accuracy was unchanged. I’m now working on the full dataset of one image per patient, which is taking some time to process, because it’s large, but the updated code should be up by tomorrow.
In general, this method should work for any single image classification dataset, where physical structure, or coloring, is indicative of disease. I will write a formal paper on the topic shortly.
The implications here are dramatic, and could democratize advanced healthcare –
All you need is a cheap laptop, the applicable dataset, and my software, and it seems, you can diagnose at least some conditions en mass, with great reliability, in just a few minutes. This would allow doctors to focus on only those patients that test positive, or have their results flagged as outside of the dataset, in this case reducing the caseload significantly. This is a big deal when you’re talking about a large number of people. By the same logic, this software allows you to reliably diagnose thousands of people, in a few minutes, again, with high accuracy.
You should run this on my updated algorithms, available on ResearchGate.
Here’s the command line code in Ocatve / Matlab:
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
