In a previous article, I showed that you can use the nearest neighbor algorithm to build a simple graph based upon which vectors in a dataset are nearest neighbors of one another. In simple terms, if two vectors are nearest neighbors, then you connect them with an edge. Once you do this for all vectors in the dataset, you will have a graph. It dawned on me earlier today that you can define a measure of dataset consistency by analyzing the properties of the resultant graph. Specifically, take the set of maximal paths in the dataset  , and label the vertices with their classifiers. Now, for each such path in , simply take the entropy of the distribution of classifier labels. This is exactly the technique I introduced in another previous article, but I suppose I didn’t make it plain that it can apply to any dataset. You can also perhaps use this to measure whether any errors are due to truly similar classes by first converting the labels to measure-based classifiers, using the method I introduced in the article before this one. That is, if the errors only appear where two classes are truly similar, then maybe that’s the way it is and that’s the best you can do, or, you can somehow tighten your lens on the dataset, which is something you can actually do in my model of machine learning.
, and label the vertices with their classifiers. Now, for each such path in , simply take the entropy of the distribution of classifier labels. This is exactly the technique I introduced in another previous article, but I suppose I didn’t make it plain that it can apply to any dataset. You can also perhaps use this to measure whether any errors are due to truly similar classes by first converting the labels to measure-based classifiers, using the method I introduced in the article before this one. That is, if the errors only appear where two classes are truly similar, then maybe that’s the way it is and that’s the best you can do, or, you can somehow tighten your lens on the dataset, which is something you can actually do in my model of machine learning.
To be perfectly clear, if any given path in contains more than one classifier, then that path by definition implies that the nearest neighbor algorithm will generate an error, and therefore, the dataset is what I would call not locally consistent. Here’s a brief proof:
Assume that  and
and  are both vertices in some path
are both vertices in some path  within the set . Because they are both part of the same path, there must a subset of that connects to , which we’ll call
within the set . Because they are both part of the same path, there must a subset of that connects to , which we’ll call 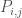 . Assume that the classifier of is
. Assume that the classifier of is  and that the classifier of is
and that the classifier of is  , for
, for  . It follows that as we traverse , beginning at , the classifiers of the vertices along that path must at some point change from to , and let
. It follows that as we traverse , beginning at , the classifiers of the vertices along that path must at some point change from to , and let  be the edge where this change occurs. Note that it could be the case that
be the edge where this change occurs. Note that it could be the case that 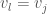 . Because
. Because  is the nearest neighbor of
is the nearest neighbor of  , and by definition the classifiers of and are unequal, it is the case that the nearest neighbor algorithm generated an error when given the input .
, and by definition the classifiers of and are unequal, it is the case that the nearest neighbor algorithm generated an error when given the input .
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
