Last night, I came to the rather obvious, but in my opinion fascinating conclusion, that there are more binary  matrices than there are graphs with
matrices than there are graphs with  vertices. Stated differently, not all binary matrices correspond to graphs. This is because of the way graphs are generally represented as matrices, where entry
vertices. Stated differently, not all binary matrices correspond to graphs. This is because of the way graphs are generally represented as matrices, where entry 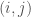 is 1 only if vertex
is 1 only if vertex  is adjacent to vertex
is adjacent to vertex  . In an ordinary, undirected graph, a vertex is never adjacent to itself, and because the edges are undirected, if vertex is adjacent to vertex , then vertex is adjacent to vertex . As a result, if a given matrix represents a graph, then it must be the case that entry
. In an ordinary, undirected graph, a vertex is never adjacent to itself, and because the edges are undirected, if vertex is adjacent to vertex , then vertex is adjacent to vertex . As a result, if a given matrix represents a graph, then it must be the case that entry  , since a vertex is never adjacent to itself, and entry
, since a vertex is never adjacent to itself, and entry  , since the edges are undirected. Therefore, the set of matrices that correspond to graphs is smaller than the set of all matrices.
, since the edges are undirected. Therefore, the set of matrices that correspond to graphs is smaller than the set of all matrices.
In fact, you can easily show that the portion of matrices that correspond to graphs goes to zero as increases. There are a maximum of choose  edges in a graph of order . Therefore, the number of labelled graphs on vertices is
edges in a graph of order . Therefore, the number of labelled graphs on vertices is  . In contrast, the number of matrices is
. In contrast, the number of matrices is 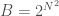 . The ratio
. The ratio 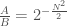 , which approaches zero as approaches infinity. Since you can trivially construct a binary string from a binary matrix by appending row
, which approaches zero as approaches infinity. Since you can trivially construct a binary string from a binary matrix by appending row  to the end of row , it follows that the portion of binary strings of length that correspond to graphs approaches zero as approaches infinity.
to the end of row , it follows that the portion of binary strings of length that correspond to graphs approaches zero as approaches infinity.
As a result, graphs, as a class of mathematical objects, are fewer in number than binary strings for any given order.
This might seem like it’s just some high school combinatorics, but it points to something profound, if you consider this fact in the context of complexity. Specifically, you can show that most strings of a given length are random in the sense that their Kolmogorov complexity is approximately equal to their length. Stated mathematically, if  is a string, and is Kolmogorov-random, then
is a string, and is Kolmogorov-random, then  . This implies that compressible strings are actually rare, despite the fact that most of what we see in the world is compressible. That is, the everyday objects you see have significant symmetries, which necessarily implies that they are not Kolmogorov-random, using any sensible representation of the object. For example, the laptop I’m using to write this article is symmetrical both horizontally and vertically, down to reasonable levels of measurement. As a result, I can reconstruct a reasonable image of the entire laptop given only a fraction of an image of the laptop.
. This implies that compressible strings are actually rare, despite the fact that most of what we see in the world is compressible. That is, the everyday objects you see have significant symmetries, which necessarily implies that they are not Kolmogorov-random, using any sensible representation of the object. For example, the laptop I’m using to write this article is symmetrical both horizontally and vertically, down to reasonable levels of measurement. As a result, I can reconstruct a reasonable image of the entire laptop given only a fraction of an image of the laptop.
This is also true of physics itself at our scale of observation, in that the outputs of Newton’s equations are never Kolmogorov-random, since they are by definition computable. That is, because Newtonian physics is written in the language of computable functions, it is necessarily the case that the behavior of Newtonian objects is compressible. For example, if you track the path of a baseball thrown across home plate, you will produce a curve that is Newtonian, and therefore, of a very low complexity, when constructed using any sensible scale of observation. It is, therefore, at least anecdotally fair to conclude that the distribution of complexities of everyday objects differs significantly from the distribution of complexities of binary strings. Specifically, most binary strings are Kolmogorov-random, whereas most everyday objects are not.
This suggests a purely mathematical question about the distribution of complexities over sets of mathematical objects. Specifically, in this case, what is the distribution of the complexities over the set of graphs of a given order?
Intuitively, it seems like graphs should have a distribution of complexities that is similar to the distribution of complexities of binary strings. Let’s imagine a binary string  . If each
. If each  , then the string will have a low complexity. Similarly, if each
, then the string will have a low complexity. Similarly, if each  , then the string will have a low complexity. In fact, the complexity of the compliment of any given string can differ by at most a constant from the original string, since we can write a simple program that can take the compliment of any given string, the complexity of which will not depend upon the string in question. Therefore, the average complexity over all strings with a given number of bits set to one is symmetrical as a function of the number of bits that are set to one.
, then the string will have a low complexity. In fact, the complexity of the compliment of any given string can differ by at most a constant from the original string, since we can write a simple program that can take the compliment of any given string, the complexity of which will not depend upon the string in question. Therefore, the average complexity over all strings with a given number of bits set to one is symmetrical as a function of the number of bits that are set to one.
Now let’s consider graphs using analogous reasoning, and consider a graph as a set of 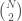 edges, each of which is either included or not. If we begin with an empty graph, intuitively, this graph should have a low complexity, since it contains no edges. This is supported by the associated graph matrix, which will consist of nothing but zeros. Similarly, if we consider a complete graph, which will include all possible edges, this graph should again have a low complexity, since it has a simple rule of construction: connect every pair of vertices. This is again supported by the associated graph matrix, which will consist of nothing but ones (except along the diagonal). Again, the complexity of a graph and its compliment can differ by at most a constant, since we can write a simple program that calculates the complement of any graph, that will not depend upon the graph in question. Therefore, the average complexity for a graph with a given number of edges will again be symmetrical as a function of the number of edges. Note that we are ignoring yet another detail, which is that we will need a separate program that takes a matrix, and actually displays a graph. But again, you can write a rudimentary program that does exactly this, the complexity of which will not depend upon the graph in question.
edges, each of which is either included or not. If we begin with an empty graph, intuitively, this graph should have a low complexity, since it contains no edges. This is supported by the associated graph matrix, which will consist of nothing but zeros. Similarly, if we consider a complete graph, which will include all possible edges, this graph should again have a low complexity, since it has a simple rule of construction: connect every pair of vertices. This is again supported by the associated graph matrix, which will consist of nothing but ones (except along the diagonal). Again, the complexity of a graph and its compliment can differ by at most a constant, since we can write a simple program that calculates the complement of any graph, that will not depend upon the graph in question. Therefore, the average complexity for a graph with a given number of edges will again be symmetrical as a function of the number of edges. Note that we are ignoring yet another detail, which is that we will need a separate program that takes a matrix, and actually displays a graph. But again, you can write a rudimentary program that does exactly this, the complexity of which will not depend upon the graph in question.
As a result, we have established that the distribution of complexities over the set of binary strings necessarily has some structure in common with the distribution of complexities over the set of graphs. At the same time, the portion of strings that correspond to graph matrices approaches zero as the length of the string approaches infinity. This suggests that the set of binary strings contains a subset that is, in terms of the distribution of its complexities, similar to itself.
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
