Introduction
I’ve already introduced a new model of A.I. that allows for autonomous real-time deep learning on cheap consumer devices, and below I’ll introduce a new algorithm that can solve classifications over datasets that consist of tens of millions of observations, quickly and accurately on cheap consumer devices. The deep learning algorithms that I’ve already introduced are incomparably more efficient than typical deep learning algorithms, and the algorithm below takes my work to the extreme, allowing ordinary consumer devices to solve classification problems that even an industrial quality machine would likely struggle to solve in any reasonable amount of time when using traditional deep learning algorithms.
Running on a $200 dollar Lenovo laptop, the algorithm correctly classified a dataset of 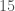
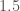
All of this work is derived from the algorithms that I described in a brief note, yesterday, but the clustering algorithm itself is the same clustering algorithm that I introduced about a year ago, which is rooted in information theory: I’ve simply replaced the operator in the original algorithm with one that lends itself to efficient comparison of mass-scale observations.
All of the code necessary to generate the dataset, and apply the algorithm, is attached below.
Comparing Mass-Scale Observations
The core idea is that the dataset consists of elements that have plainly different categories, when expressed as real world objects, but that the elements contain so many observations, that uncovering this fact would be intractable, at least when using traditional machine learning techniques. Even using my typical clustering algorithms, which always have a low-degree polynomial runtime, these problems are not tractable on a consumer device, but could probably be solved on a commercial grade machine.
We can easily imagine these types of real-world problems: for example, you could have a high-resolution sensor that produces an enormous number of observations, tasked with discerning between two plainly different physical objects. To a human observer, the distinction would be trivial, but to a machine that is flooded with hundreds of millions of observations, this task is probably intractable using traditional machine learning techniques, for the simple reason that there is just too much information to sift through in order to uncover what could be a simple structure in the dataset.
The intuition that I noted yesterday, that underlies the operators that I’ve developed, is that by simply sorting a dataset, we can uncover a lot of amount of information about the dataset.
Let’s consider the most basic case, of two enormous sets of floating point numbers, that both contain the same number of items. Further, let’s assume that a human observer would, upon inspection, conclude that the two sets of numbers are similar, in that randomly selecting numbers from the two sets produces roughly the same distribution of numbers. It follows that if we sort these two sets of numbers, then at each ordinal entry in the two sorted lists, we should find roughly comparable numbers. This seems like a trivial insight, but if instead we consider two drastically different sets of numbers, then this won’t be true, since the minimum, maximum, and everything in between, will be drastically different in value, causing corresponding ordinal entries to differ significantly. As a result, by simply taking the sum over the square of the difference between corresponding entries in two sorted lists of numbers, we can construct a meaningful measure of the difference between the two sets of numbers.
The most important aspect of this approach, is that sorting, and taking summations, over even tens of millions of observations can be done in seconds in languages like MATLAB and Octave. This allows us to quickly compare the difference between two enormous sets of numbers. We can, therefore, also take an enormous set of vectors, sort each dimension, and apply the same technique, separately, to each dimension, thereafter taking the sum over the result for each dimension, thereby producing a measure of total difference between two enormous sets of vectors. We can then treat this entire process as an operator that is applied to two sets of vectors, and use it as the primary operator in my “within-delta” clustering algorithm.
Note that I have in other cases, also used other operators, such as the intersection operator, and so the approach to A.I. that I introduced about a year ago is truly general, and can be applied to non-Euclidean spaces. But in this case, we are substituting the norm operator for reasons of efficiency, even though the data is itself Euclidean, which would ordinarily warrant use of the norm operator.
Identifying Macro-States of a Thermodynamic System
We can now consider a simple example of a system comprised of particles of gas trapped in a volume, where each observation of the system consists of 
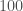
The actual classification task is simple: in one class of states, the gas is compressed in a small volume, and in the other, the volume expands, allowing for a broader set of possible positions for the particles. To a human observer, the distinction between these two states would be obvious, assuming you could observe the macroscopic boundaries of the volume. But to a machine that’s being given sensor data, that in this case generates tens of millions of observations, it will probably not be possible to classify this data using any technique that requires significant manipulation of the underlying point data, absent significant amounts of time. As a result, this example highlights the power of this approach, which allows machines to identify well defined categories in enormous datasets, the sheer size of which obfuscates the categories.
Though the classification question is in this case simple, the actual difference in volume between the two categories is certainly not extreme: one category is a cube bounded within [0,1] in all three dimensions, and the other is a cube bounded within [0, 1.25] in all three dimensions. As a result, this algorithm is almost certainly useful for a wide variety of real-world classification problems that involve an otherwise intractable number of observations.
OCTAVE CODE
My core A.I. library, which includes all background functions, is available here.
The particular code for this algorithm is below:
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
