I’m in the middle of writing a formal paper and related software on automated hypothesis testing, but I thought I’d outline the basic idea, which is that information theory can be used to provide an absolute context in which error is evaluated to determine whether a hypothesis is exact, imprecise, or simply incorrect. I explained the basic idea on Twitter last week, which is that every observation carries a certain amount of information, and because length itself can be associated with information, we can therefore measure the net information of a hypothesis as the difference between (x) the information content of an observation less (y) the information content of the error between the observation and the hypothesis.
Error, Length, and Information
I’ll present a more fulsome discussion of this topic in a formal research paper I’m working on, but in short, any physical system can be used to store information, so long as you can identify and control its states. As a result, a physical system that can be in any one of 

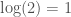
Now consider a line with a point upon it at some location. Each possible location for the point will represent a unique state of this system. And of course, the longer the line is, the more possible locations there will be for the point, producing a system that has a larger number of states as the length of the line increases. Again, this is not how normal people think about lines, since they’re primarily conceptual devices imposed upon empty spaces, or objects, and not technically “real”. But, if you had, for example, some string, and a piece of glitter, you could use this system to store information. As a practical matter, if the string is unmarked, it will be hard for you to tell the difference between the possible locations for the speck of glitter along its length. To remedy this, you could mark the string with equally spaced lines that indicate the beginning of one segment and the end of another. Though this is decidedly primitive, a string with
As a practical and theoretical matter, there will be some minimum length, below which, you cannot measure distance. That is, your vision is only so good, and even if you have the assistance of a machine, its resolution will still be finite. Therefore, in all circumstances, there will be some minimum length 


Similarly, there will be some practical limit to the number of objects 


For any given observer in a particular context, the values of 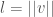

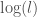
As a result, every error, which will be the norm of the difference between two vectors 

To make things more concrete, let’s consider an example involving a given observed level of RGB luminosity 


and therefore, the information associated with the error is 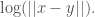

I’ve chosen 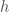



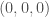
initial_lum = 50
obs_color = ones(1,3)*initial_lum;hyp_lum = 0;
hyp_color = [hyp_lum hyp_lum hyp_lum];h = 0;
inf_cont = log2(norm(obs_color));
while(h >= 0)
hyp_lum = hyp_lum + 1;
hyp_color = [hyp_lum hyp_lum hyp_lum];error = norm(obs_color – hyp_color)
h = inf_cont – spec_log(error)
endwhile
figure, imshow(display_color(obs_color))
figure, imshow(display_color(hyp_color))
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
