INTRODUCTION
Mathematical Coincidence
In two previous articles (Part I, and Part II), I presented a mathematical model of coincidence, rooted in Carl Jung’s notion of synchronicity. Part I discussed some of the basic mathematics and concepts, and Part II showed how these concepts can be used as a practical way to deliver messages to a recipient that is not expecting to receive a message. There is a lot of information in the prior articles, but it is nonetheless possible to read only this article, and still understand what’s going on, so I’ll begin by revisiting the following definition of coincidence:
If I had to define coincidence, I would say it has two components: (a) a low probability, and (b) contextual relevance.
One of the examples of coincidence I gave in the original article on the topic is the following:
Imagine walking out of a store having just purchased a bright orange hat, when suddenly, someone throws an orange at you. Both events are low probability in the ordinary course, and the latter event of getting hit by an orange is relevant, because it intersects in property with the item you just purchased. And you would be completely certain the event was deliberate, even if it seemed superficially impossible for that to be the case.
This definition formalizes the difference between something that is merely unlikely, and something that is both unlikely, and also directed at you, in a manner that lends itself to measurement, since you can measure both the probability of the event in question, and the extent to which it intersects with your life experiences and expectations, though the latter will of course involve some judgement, the mechanization of which will introduce some imprecision. But the point is, this formalization allows us to turn coincidence into a mathematical concept that can be used as a tool to deliver messages to recipients that are not expecting to receive a message.
The following is an example I gave in the previous article, that highlights the difference between an unlikely event, and a coincidence, as I’ve defined it:
[It’s] the difference between seeing super model Amber Valletta walking through the streets of New York City, and instead seeing super model Amber Valletta wearing a t-shirt with your face on it. The former is an unlikely event, whereas the latter event is not only unlikely, but also personal, since she’s wearing a t-shirt with your face on it, suggesting the circumstances are almost certainly the product of design, and not the product of the undisturbed operations of nature.
Delivery of the message is effectuated by orchestrating a coincidence that first gets the attention of the recipient, and in Part II, I presented the outlines of how you can encrypt not only the attention-getting coincidence, but also the message that follows. The net result is that you can deliver an encrypted message in plain sight, in public, and as a general matter, only the intended recipient will receive and understand the message.
In this article, I’m going to present a practical, mathematical model of human association, and ultimately, two mathematical languages on sets: one based upon the union operator, and another based upon the intersection operator. Both languages can be used to convey messages to recipients that don’t expect to receive a message, provided a coincidence is orchestrated to garner the recipient’s attention. Though technically independent of coincidence, by combining these languages with the use of coincidence, we can develop a rigorous mathematical model of how to deliver an encrypted message to a recipient that is not expecting a message, in a mechanized manner, in plain sight, publicly, and as a general matter, no one will know who the intended recipient is, or the contents of the message, other than the intended recipient.
THE PRACTICAL MECHANICS OF ASSOCIATION
Signals and Mappings
Association is, in its most fundamental form, a mapping from an input stimulus to some stored memory. For example, if I see an orange, I’ll probably conjure memories about oranges, perhaps imagining the last orange I ate, or the Matisse painting in my old apartment, featuring three oranges. In both instances, I’ve taken an input signal, i.e., an actual physical orange, and mapped it to some set of memories. As a result, we’ll need some method of comparing an exogenous input signal to what’s in memory in order to produce associations. If we imagine this taking place on a machine, rather than in human memory, we can easily think of practical ways to get this done. For example, by scanning a dataset of images for an orange, and returning every image that contains an orange as part of an association cluster. This probably isn’t the result we ultimately want, but it works as a simple example of mechanized human psychological association.
How to analyze exogenous signals like images is a well-understood topic in A.I., and if you’re interested in my views on the subject, this article on vectorized image processing provides a solid overview on my approach to A.I., which is to use information theory and computer theory to give objective answers to questions of discernment and observation. In contrast, the main focus of this article is how to manipulate associations to deliver messages, and so I’ll assume that signals can be analyzed and mapped to a dataset by a predefined algorithm. This means that the approach discussed in this article will be agnostic on how you perceive an orange, and what you associate with an orange, treating your perceptions and associations as fixed, and known to the sender. Instead, we will focus on exploiting those associations to deliver messages.
Types of Association
Though I’m sure the actual biology of association is complex, I’m going to divide association into three simple categories: similarity, observation, and intersection. There are other mechanics that can generate an association in someone’s mind (e.g., unconscious instinct), but the goal is to develop a model that works as a means of communication, and covers how people actually think, and construct meaning, generally.
Association by similarity is intended to cover cases where two signals are sufficiently similar to be considered associated with one another. For example, when presented with two pictures of sufficiently similar faces, it’s reasonable to make a mental association between the two, since each will likely trigger a memory of the other upon observation.
Association by observation is intended to cover cases where signals are associated because they occur proximately in time, space, or both time and space. So, for example, if a screen displays colors randomly, and blue is always almost immediately followed by green, then you’ll probably make a mental association between blue and green. Note that unlike association by similarity, there is no mathematical operator that compares the signals in question. That is, the signals are associated by virtue of their proximity in time and space, rather than any endogenous aspect of the two signals. As a result, association by observation allows for a much wider set of associations than association by similarity, since you can, in theory, cause any two objects or ideas to become associated with each other, simply by causing them to be repeatedly proximate in time and space.
Association by intersection is intended to cover cases where signals are associated because they share some common property. This is the case covered by the original example of coincidence provided above, where the orange hat is tacitly associated with the orange fruit projectile. This is because both objects share the property of being orange in color. In this case, there is a comparison between the two objects in question, but it is not a Euclidean measure. Rather, it’s probably best thought of as implemented using an intersection operator as applied to a set of characteristics. So returning to the example, the orange hat has a set of properties, which might include, e.g., “woolly”, “plush”, and of course, “orange”. The orange fruit has a set of properties which might include, e.g., “acidic”, “firm”, and, of course, “orange”. When we apply the intersection operator to these two sets of properties, we’ll get the property of being orange in color, thereby triggering an association.
In this article, I’m going to use these definitions only as a tool to think more meaningfully about associations, but in a follow up article, I’ll present a rigorous mathematical treatment of each category of association, together with related software. For those that can’t wait, association by similarity is pretty easy to implement, especially using my notion of “within-delta”, which you can read about in my original paper on A.I. Association by observation can be implemented using variants of my projectile tracking software (just test for proximity in time, space, or, time and space), and implementing association by intersection is trivial.
Modeling Associations
To formalize and implement this approach, we’ll need three components: a signal, an observer, and a dictionary. A signal can be any finite collection of exogenous sensory data, from a t-shirt, to a car crash. An observer is a human being that will observe a signal, and map it to some dictionary, which is a finite collection of bundles of stored sensory information, indexed by integers.
So, for example, I could show you an orange. In this example, the signal is the orange, the observer is you, and the dictionary is your memory, which we’re going to treat as an integer-indexed collection of bundles of sensory data. Further, we’ll assume that upon seeing the orange, an association cluster is produced by your mind, which we’ll model as a set of integers, representing the indices of the dictionary entries triggered by observing the input orange.
In reality, seeing an orange will probably generate something that is better modeled as a discrete graph, where we can imagine the input orange itself in the center, and then as you proceed away from that central node, you get more remote associations. So, right next to the input orange node, you’d have things that are immediately associated with an orange, like its scent, taste, and color, whereas further out, you might have paintings that involve oranges. While this type of granularity is probably important in designing software that simulates human behavior, it is not important to the design of software that delivers messages based upon associations. That is, even if we capture only a crude set of likely associations, this will probably work just fine for what we’re doing, which is sending messages, not building robots.
I’m assuming that we already have software that can process the signal, and produce an association cluster, and so the goal will be to design software on top of that, to send messages using the recipient’s associations, which are assumed to be fixed, and known to the sender. Even though consumer behavior is a heavily studied topic, writing software that actually maps signals to associations is certainly not a trivial task. But the reality is, there’s so much consumer and social media data available, that this problem has almost certainly been solved.
DELIVERING MESSAGES USING ASSOCIATIONS
Signal and Association
Formalizing what we’ve described a bit more, every exogenous signal 

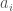
Two Primal Languages on Sets
Let’s assume that we’ve already gotten the recipient’s attention using a coincidence, and would now like to convey a message using a set of signals 

Expressed mathematically, stating the meaning of a set of signals in each language is straightforward. Specifically, the meaning of 
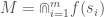
and the meaning of
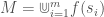
That is, the meaning of 
Note that this is visceral meaning, not linguistic meaning, in that what is ultimately conveyed is raw sensory information that is intended to have an abstract, net effect on the recipient of the message. In some sense, these languages are more powerful than mere words, because what you can conjure in the mind of the recipient is that which hits you hardest – the face of someone you love, the blouse they wore the last time you saw them, the color of their iris, the details of their eyelashes. These are the things that words are intended to describe, whereas these languages provide a means to reference them directly, creating a mechanized, psychological portrait of raw sensory information in the mind of the recipient, that can nonetheless resolve to a single coherent meaning.
As an example, assume that
With these ideas, we can now think rigorously about whether a given set of signals has a coherent meaning, by considering the rate of convergence of the cardinality of
Though it’s obviously much harder to measure, what this method allows you to do is deliver two messages: returning to the example above, the meaning of
These languages could allow emotionally sensitive people to communicate in incredibly sophisticated ways, because it could allow for subtle changes to the same literal message due to the inclusion of different emotional triggers. This is what artists do, and this is what expert copywriters do as well – manipulate you. But, these languages could allow for a machine to study you, and color messages in a way with emotional triggers that would be simply impossible for anyone else detect. The encryption acheived if this were successful would be essentially impossible to crack. A truly sensitive person doesn’t need much – a subtle change in color, or facial expression, and the literal message is unchanged, but the emotional message might let you know the whole thing was bull shit. This means that even if social media companies know everything about your life, the inclusion of minor details could completely change the context of the message, though the literal message remains unchanged.
It’s the emotional mustache on the message:

Marcel Duchamp, L.H.O.O.Q (1919)
YOU REALLY HAVE TO REGULATE THIS BUSINESS
Two people that know each other well can do all of this without software, which is to have a conversation in front of strangers, that only the two of them truly understand, because they have private jokes, gestures, and sounds, that only the two of them truly understand. That’s not a problem, because that’s the reward for taking the time to actually get to know another human being.
The problem is, the mechanized incorporation of social media data into traditional media could allow for what would effectively be brainwashing on a mass scale, and I’m not exaggerating. Just imagine how much harm you could do during a broadcast to millions of people by simply deliberately selecting wardrobes, targeted words, people’s faces, hairstyles, images associated with news stories, even the fonts used during the broadcast, with the deliberate intent to upset viewers that have been targeted by A.I. algorithms, for whatever reason. Software of the type described above could be used to generate instructions in making these selections in a manner that maximizes harm, and minimizes evidence of wrong doing. The idea that people won’t do this is simply ridiculous – Harvey Weinstein went through far greater efforts for the unprofitable purpose of raping women. This is something that can actually make money, swing elections, or suppress competition, so, I’m certain that if it’s not already happening, it will happen.
If you think otherwise, then you don’t know people.
So, while I’m proud of this work, it’s also a warning to society, that this stuff is real, and unless we regulate the media, which we used to, presumably in large part for similar reasons, we’re in serious trouble.
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
