Attached is an updated version of an algorithm I introduced in a previous post that can imitate a dataset, thereby expanding the domain of a dataset. This version is incomparably more efficient than the previous version, since it uses my new categorization and prediction algorithms. In the example I’ve attached, which imitates the shape of a 3D vase, the algorithm generates approximately 140 new points per second, and copies the entire shape in about 11 seconds, running on a cheap laptop.
Below are images showing the original shape, the point information, and the replicated shape generated by the algorithm.
-
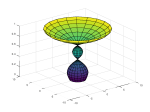
- The original shape.
-
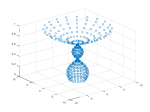
- The original point data.
-

- The copy generated by the algorithm.
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
