In a previous research note, I introduced a method of delimiting sequences of data, by testing the ratio of adjacent entries in the sequence. This process generates mutually exclusive categories, simply because it places delimiters in the sequence of data, which we can then interpret as indicators that mark the beginning and end of categories. I showed how this method can be used to quickly find the boundaries of objects in images, and of course, it can also be used to categorize data.
However, rather than read the data in the order in which it is presented, we can also compare each element to every other element, thereby generating non-mutually exclusive categories. That is, you perform the same process that I described in the previous research note, but rather than simply test adjacent entries, you test a given entry against all other entries in the dataset, as if they were adjacent. This will generate a category for each element of the dataset. We then test each element, against every other element, and if the test generates a delimiter, then we don’t include the element in question in the category in question. If the test does not generate a delimiter, then we do include the element in question in the category in question.
We can of course also produce mutually exclusive categories using this technique by simply tracking which elements have already been selected.
In the research note below this one, I noted that there is good reason to believe that there is a single objective in-context minimum difference for distinction, which I call 
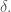
The question is then, does the delimiter process, which also produces a measure of distinction I call 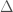
I’m going to test this hypothesis over the next few days, and follow up with the results.
Since it’s easy to generate either mutually exclusive categories, or non-mutually exclusive categories using this approach, regardless of the operator we use to compare two elements of a dataset, it suggests a more general question:
Is there is an objective, in-context level of distinction associated with every operator as applied to a dataset?
My original categorization algorithm uses the norm of the difference between two vectors to compare elements of a dataset. But my library contains algorithms that use other operators, such as intersection, inequality, and we can imagine others, like taking the union of sets. These are just trivial variations on my main theme of AI, which is to iterate through levels of distinction, and select the level that generates the greatest change in the entropy of the object in question.
Restating the question: is there a single, objective threshold value, analogous to
To test this hypothesis, we’d have to generate mutually exclusive categories using the operator in question, note the associated value of 
Discover more from Information Overload
Subscribe to get the latest posts sent to your email.
